kafka
kafka安装
首先去 Apache kafka 官网http://kafka.apache.org下载 kafka,这里我下载的是 kafka_2.12-2.1.0.tgz。
然后解压文件,修改 config/server.properties 文件,将其中的 advertised.listeners 改为你主机IP,例如:
# The address the socket server listens on. It will get the value returned from # java.net.InetAddress.getCanonicalHostName() if not configured. # FORMAT: # listeners = listener_name://host_name:port # EXAMPLE: # listeners = PLAINTEXT://your.host.name:9092 #listeners=PLAINTEXT://:9092 # Hostname and port the broker will advertise to producers and consumers. If not set, # it uses the value for "listeners" if configured. Otherwise, it will use the value # returned from java.net.InetAddress.getCanonicalHostName(). advertised.listeners=PLAINTEXT://192.168.1.220:9092
改好后,执行下面两条语句就可以启动kafka:
bin/zookeeper-server-start.sh config/zookeeper.properties bin/kafka-server-start.sh config/server.properties &
说明:advertised.listeners 是 broker 给 producer 和 consumer 连接用的,如果没有设置,就使用 listeners,而如果主机IP没有设置的话,就使用 java.net.InetAddress.getCanonicalHostName() 方法返回的主机名。
kafka docker 安装
这里涉及 zookeeper/kafka/kafkamanager 三个服务的安装。
falkafka-compose.yml
version: '3.6'
services:
falzookeeper:
image: 192.168.1.166:8083/zookeeper-falsec
volumes:
- "zoodata:/data"
- "zoodatalog:/datalog"
- "zoologs:/logs"
networks:
- falnet
deploy:
placement:
constraints:
- node.role == worker
falkafka:
image: 192.168.1.166:8083/kafka-falsec
volumes:
- "kafka:/kafka"
depends_on:
- falzookeeper
networks:
- falnet
ports:
- "9092:9092"
deploy:
placement:
constraints:
- node.role == worker
falkafkamanager:
image: hlebalbau/kafka-manager:latest
depends_on:
- falzookeeper
ports:
- "9000:9000"
environment:
ZK_HOSTS: "falzookeeper:2181"
APPLICATION_SECRET: "random-secret"
command: -Dpidfile.path=/dev/null
networks:
- falnet
deploy:
placement:
constraints:
- node.role == worker
volumes:
zoodata:
zoodatalog:
zoologs:
kafka:
networks:
falnet:
external: true
name: falpolicy_falnet
kafka的使用
# 创建topic ./kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --replication-factor 1 --partitions 1 --topic zipkin # 查看topic列表 ./kafka-topics.sh -list -zookeeper 127.0.0.1:2181 # 创建生产者 ./kafka-console-producer.sh --broker-list 192.168.30.60:9092 --topic test # 创建消费 ./kafka-console-consumer.sh --bootstrap-server 192.168.30.60:9092 --topic test --from-beginning # 有了生产者和消费者,就可以模拟生产者发送消息,消费者接收消息了,试试吧。
数据存储位置
默认存储在:/tmp/kafka-logs/
注:如果由原来的新版本降级到老版本,但新版本上 kafka-logs 目录里的数据没删除,可能会报错导致无法启动kafka。
除了手工创建topic外,你也可以配置你的broker,当发布一个不存在的topic时自动创建topic。
查看主题(topic)详细信息$ bin/kafka-topics.sh --zookeeper localhost:2181 --topic test --describe
发送消息
Kafka提供了一个命令行的工具,可以从输入文件或者命令行中读取消息并发送给Kafka集群。每一行是一条消息。
运行producer(生产者),然后在控制台输入几条消息到服务器。
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-replicated-topic >This is a message >This is another message
消费消息
Kafka也提供了一个消费消息的命令行工具,将存储的信息输出出来。
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic my-replicated-topic
如果你发送消息,就可以在这里接收到了。
提示:没有 my-replicated-topic,脚本居然会自动创建出来这个topic。
发布/订阅、点对点的使用
- 与ActiveMQ不同,kafka使用 group 来解决这两个功能。同一个group里的多个消费者,只有一个会消费数据;如果要多次消费同一个数据,类似与发布/订阅模式,
消费者需要再创建不同的group。 - 一个group里可以包含多个消费者进程,而不是单个进程。也就是说我可以创建多个storm实例,每个storm都使用同一个group,但不会重复消费数据。
kafka 核心名词解释
- Broker:消息中间件处理结点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群。
- Topic:一类消息,例如设备流量日志、操作日志等都可以以topic的形式存在,Kafka集群能够同时负责多个topic的分发。
- Partition:分区,topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。更大分区能处理更大并发数据。
- Segment:分段,partition 物理上由多个segment组成。
- offset:每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中。partition中的每个消息都有一个连续的序列号叫做offset,用于partition唯一标识一条消息。
存储结构
partiton 文件存储方式
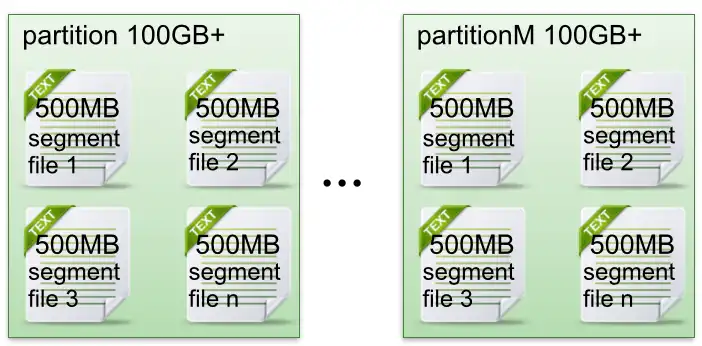
- 每个partion(目录)类似一个巨型文件被平均分配到多个大小相等segment(段)数据文件中。但每个段segment file消息数量不一定相等,这种特性方便 old segment file 快速被删除(关于Kafka日志保留策略我们后面会讲到)。
- 每个partiton只需要支持顺序读写就行了,segment文件生命周期由服务端配置参数决定。
partiton 中 segment 文件存储结构
segment 由 index 索引文件和 data 数据文件两部分组成,这2个文件成对出现,分别对应后缀 .index 和 .log:

segment文件命名规则是这样的,partion 全局的第一个segment 从0开始,后续每个 segment 文件名为上一个segment文件最后一条消息的offset值。数值最大为64位long大小,19位数字字符长度,没有数字用0填充。
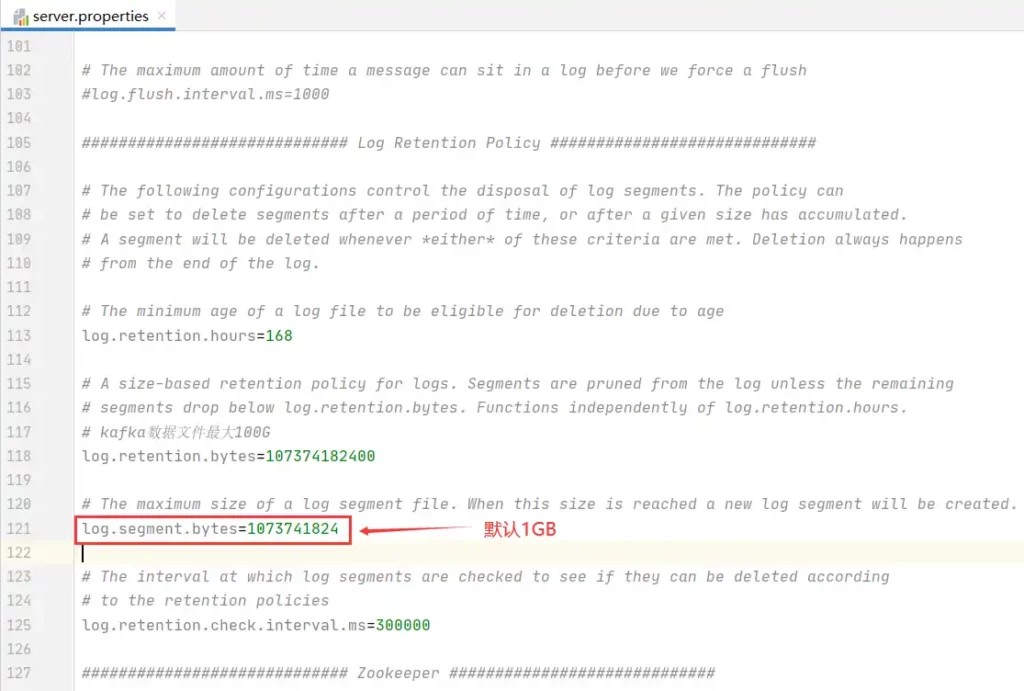
另外,segment文件大小是可以在 Kafka日志保留策略那调整的,默认是1GB:
下图显示了 segment 中 index 文件和 data 文件的物理结构关系:

上图可以看到,index 索引文件存储大量元数据,数据文件存储大量消息,索引文件中元数据指向对应数据文件中message的物理偏移地址。 其中以索引文件中元数据3,497为例,依次在数据文件中表示第3个message(在全局partiton表示第368772个message)、以及该消息的物理偏移地址为497。
segment 中 message 数据结构
从上图我们知道了 segment data数据文件是由许多 message 组成的,下面详细说明了 message 的数据结构:

参数说明:
| 关键字 | 解释说明 |
|---|---|
| 8 byte offset | 在parition(分区)内的每条消息都有一个有序的id号,这个id号被称为偏移(offset),它可以唯一确定每条消息在parition(分区)内的位置。即offset表示partiion的第多少message |
| 4 byte message size | message大小 |
| 4 byte CRC32 | 用crc32校验message |
| 1 byte “magic” | 表示本次发布Kafka服务程序协议版本号 |
| 1 byte “attributes” | 表示为独立版本、或标识压缩类型、或编码类型。 |
| 4 byte key length | 表示key的长度,当key为-1时,K byte key字段不填 |
| K byte key | 可选 |
| value bytes payload | 表示实际消息数据。 |
kafka 保留策略 – Retention Policy
所谓保留策略就是日志清理策略。曾在客户那将kafka分区增加到100个,然后每隔1小时 kafka-logs 目录增加 32GB 文件,没过2天磁盘就爆满,因此合理配置保留策略至关重要。
关键配置说明:
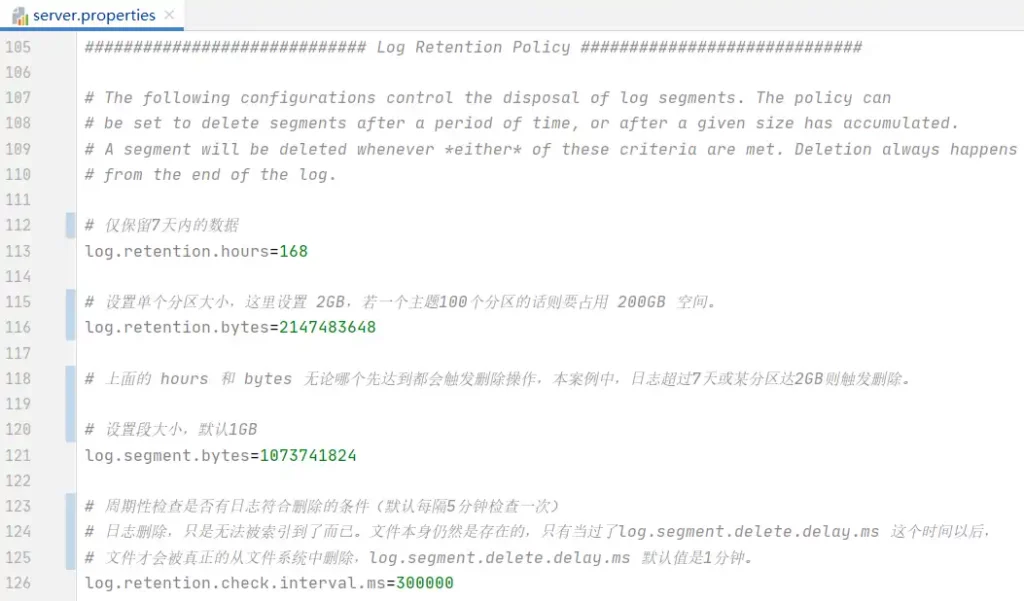
再次强调,log.retention.bytes 的设置,会作用于每一个分区上,不是指 topic 上的所有分区。
另外,虽说根据分区数和每个分区上设置大小可以计算出 kafka 最大占用磁盘空间200GB,但工作中实际却发现达到了300GB(从400GB降倒300GB),多出了100GB,这应该与 log.segment.bytes segment文件大小有关,此值默认是1GB,100个分区就是100GB,将此值改小一半后,过了几分钟 kakfa磁盘总大小变成了 288G,观察许久没有超出,设备日志流量是在不停地发送过来的,再过2小时去看变成了 250GB。多出来的50GB哪里来的呢?
于是将客户环境 kafka 数据目录全部清空,重新等待1天,观察…….
更多 kafka 配置选项可以参考这篇官方文档:Kafka 2.1 Configuration
offset
在 kafka 中,读写topic,都涉及offset,关于 kafka 的 offset 主要有以下几个概念,如下图:
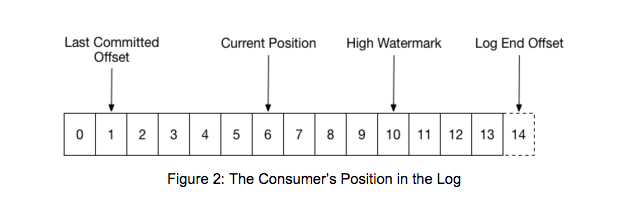
其中,Last Committed Offset 和 Current Position 是与 Consumer Client 有关,High Watermark 和 Log End Offset 与 Producer Client 数据写入和 replica 之间的数据同步有关。
- Last Committed Offset:这是 group 最新一次 commit 的 offset,表示这个 group 已经把 Last Committed Offset 之前的数据都消费成功了;
- Current Position:group 当前消费数据的 offset,也就是说,Last Committed Offset 到 Current Position 之间的数据已经拉取成功,可能正在处理,但是还未 commit;
- Log End Offset:Producer 写入到 Kafka 中的最新一条数据的 offset;
- High Watermark:已经成功备份到其他 replicas 中的最新一条数据的 offset,也就是说 Log End Offset 与 High Watermark 之间的数据已经写入到该 partition 的 leader 中,但是还未成功备份到其他的 replicas 中,这部分数据被认为是不安全的,是不允许 Consumer 消费的(这里说得不是很准确,可以参考:Kafka水位(high watermark)与leader epoch的讨论 这篇文章)。
Kafka 2.1 官方文档
允许外网访问
需要设置 advertised.listeners 的 EXTERNAL 为主机IP地址,如 192.168.1.230。

listeners 和 advertised.listeners 的区别
在公司内网部署 kafka 集群只需要用到 listeners,内外网需要作区分时 才需要用到advertised.listeners。
advertised_listeners 监听器会注册在 zookeeper 中。
当我们对 172.17.0.10:9092 请求建立连接,kafka 服务器会通过 zookeeper 中注册的监听器,找到 INSIDE 监听器,然后通过 listeners 中找到对应的 通讯 ip 和 端口;
同理,当我们对 <公网 ip>:端口 请求建立连接,kafka 服务器会通过 zookeeper 中注册的监听器,找到 OUTSIDE 监听器,然后通过 listeners 中找到对应的 通讯 ip 和 端口,例如:172.17.0.10:9094;
在 docker 中或者 在类似阿里云主机上部署 kafka 集群,这种情况下是 需要用到 advertised_listeners。
总结:advertised_listeners 是对外暴露的服务端口,真正建立连接用的是 listeners。
Kafka分区数是否越多越好?
FAQ
- Fatal error during KafkaServer startup. Prepare to shutdown (kafka.server.KafkaServer)
解决:1. 删除 /tmp/kafka-logs; 2. netstat -lnp|grep 9092;并且 kill pid; 3. 重启
kafka-manager
下载zip文件方式安装
在第一节,我们使用docker compose文件安装了 kafka-manager,这里我们再说说手动方式安装。
下载编译
cd kafka-manager ./sbt clean dist
完成后,在target目录下我们可以看到 kafka-manager kafka-manager-1.3.0.8.zip
注:java不能只安装jre,否则执行sbt命令会有问题。centos7上默认仅装了jre,我重新装了oracle jdk1.8才执行成功。
安装与配置
cd target/universal/ unzip kafka-manager-1.3.3.7.zip cd kafka-manager-1.3.3.7 vi conf/application.conf
在conf/application.conf中将kafka-manager.zkhosts的值设置为你的Kafka的 zookeeper 服务器,你还可以通过环境变量ZK_HOSTS配置这个参数值:
————————————————————————
# kafka-manager.zkhosts=”kafka-manager-zookeeper:2181″
# kafka-manager.zkhosts=${?ZK_HOSTS}kafka-manager.zkhosts="192.168.1.220:2181,192.168.1.230:2181"
————————————————————————
启动
$ /home/admin/dev/kafka/kafka-manager-1.3.3.18/target/universal/kafka-manager-1.3.3.18/bin/kafka-manager默认情况下端口为9000,你还可以通过下面的命令指定配置文件和端口:$ /home/admin/dev/kafka/kafka-manager-1.3.3.18/target/universal/kafka-manager-1.3.3.18/bin/kafka-manager -Dconfig.file=/path/to/application.conf -Dhttp.port=8080
运行界面:http://192.168.1.220:9000/
第一次进入web UI要进行kafka cluster的配置,都是一些比较简单的操作,这里就不多说了。
cluster配置
安装好后,首先要做的就是配置 cluster,这其实很简答,设置下面两个地方就可以跑起来了。
创建cluster
添加的cluster信息存储在 zoomkeeper 的 /data数据目录下,如果将此目录删除,cluster需要重新配置。
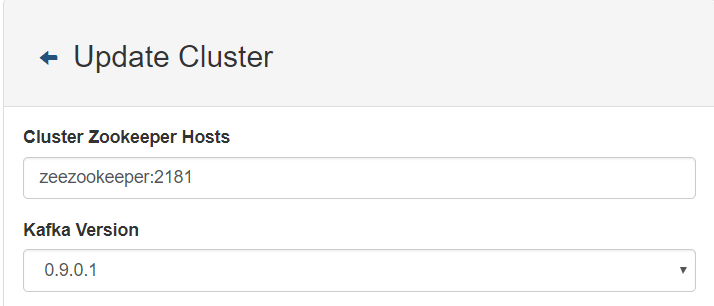
注:由于我的 kafka和 kafka-manager使用的swarm docker部署,在同一个 overlay网络下,因此直接用docker的名称falzookeeper作为host。
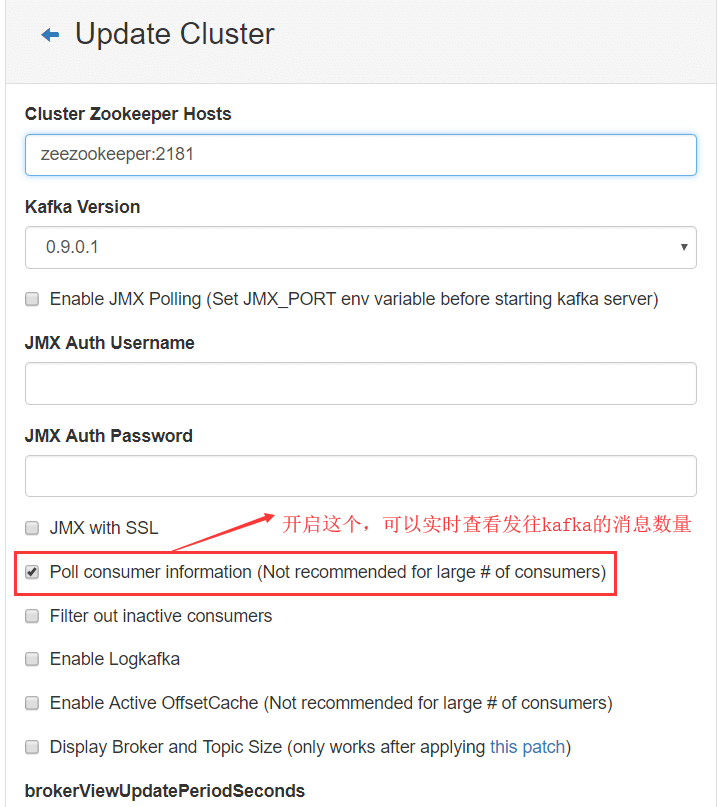
启用 Poll consumer information
这一步的目的是用来实时查看kafka接收到的消息数量,方便调试。
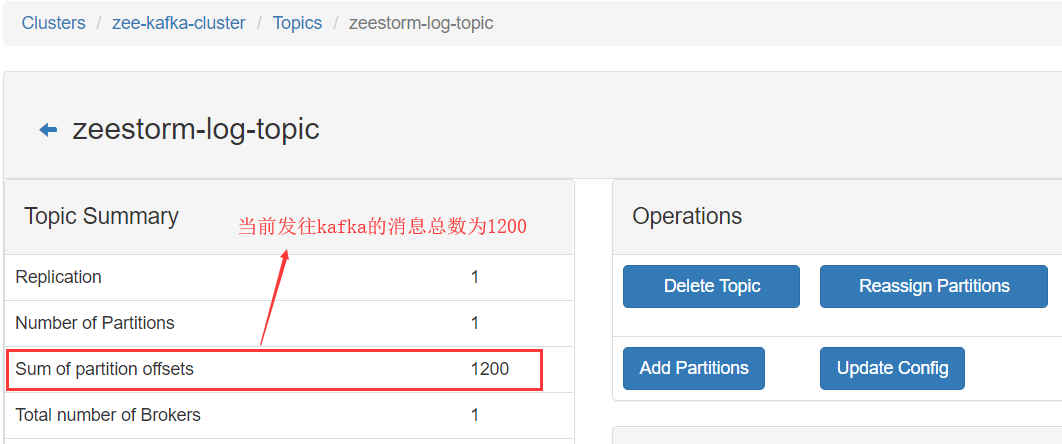
从下面这张图可以看到,当前发往kafka的消息总数为1200,而且还在不断增加中。
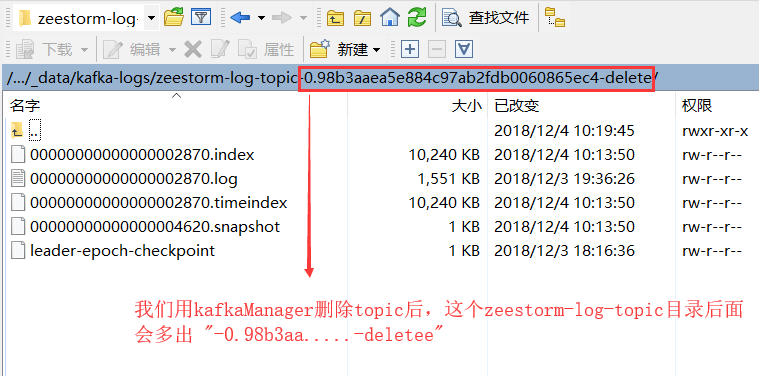
删除Topic
在 2.2.3 节的图片中,有个 “Delete Topic” 的按钮,点击后,我发现 kafka存储这个topic的文件夹被标记为delete,过一段时间后就自动删除了。
Redpanda Console 客户端(推荐)
Github地址:https://github.com/redpanda-data/console
offsetexplorer 客户端工具在Kafka服务器端配置了 SASL_PLAINTEXT 认证后一直连不上,改用此工具就简单多了,直接启动一个 Docker 即可,例如:
docker run --rm -p 8080:8080 -e KAFKA_BROKERS=192.168.1.200:9093 -e KAFKA_TLS_ENABLED=false -e KAFKA_SASL_ENABLED=true -e KAFKA_SASL_USERNAME="myname" -e KAFKA_SASL_PASSWORD="123456" docker.redpanda.com/redpandadata/console:latest