1. 问题描述
某银行防火墙日志每天的量惊人(TB级别),Storm 来不及处理,Kafka 消息越积越多,问题虽找到了,但如何解决呢?下面是2天的排查过程,原来瓶颈还是在 kafka 上,文章最后会有总结。
2. 发现 supervisor id 相同问题
由于项目使用 MicroK8S 不太好排查,于是单独在虚机里装 storm 来测(下载地址),开了一个nimbus和两个supervisor,结果 Storm UI中始终只有一个 supervisor。一番排查,原来是两个 supervisor 实例的 id 相同导致的。解决办法是,开第二个 supervisor 前先把 storm-local 目录下的内容删除,否则
storm-local/isupervisor/1650007151987 文件中已存在 supervisor id 开第二个实例就会用它。
但是这个问题在 K8S 环境里并不存在,因为 storm-local 目录没有映射出来,每次启动容器都是新的。额外说下,官方 storm 镜像把 storm-local(即 data)、logs 这2个目录被明确挪到了其他地方,具体是在
/conf/storm.yaml 中设置。继续排查……
3. Worker、Executors、Task、Component、Spout、Bolt 概念
一个 K8S 的 supervisor(即 pod 实例)并不是对应一个 worker,supervisor里可设置很多端口,一个端口可认为是一个 worker,即一个JVM,一个woker下默认有可用JVM4个。因此 JVM 由 K8S 创建,拓扑只是放在 JVM 里执行。于是再次重温一下官方这篇文章:Understanding the Parallelism of a Storm Topolog,巩固了下 Worker、Executors、Task、Component、Spout、Bolt 概念。
4. Storm CLI 再平衡 worker 出问题,任务无法平均分布在各 Supervisor 上
直接上测试总结:
- k8s yaml文件里replicas设置2启动2台 supervisor,一台始终负责拉kafka数据另一台处理数据。
- k8s yaml文件里replicas设置3启动3台 supervisor,经CLI再平衡后,旧的两台pod报”容器之间supervisor连接拒绝问题”, 执行 yeestorm-shutdown.sh 再重启 storm 后三台都正确执行了拓扑,但是接收和处理数据都在一台 supervisor 上进行了。再平衡到2台又是一台始终负责拉kafka数据另一台始终处理数据。
- 几次测下来发现,parallelismHint 似乎要设置双数,单数的话接收和处理都会在一台 supervisor上。另外,使用 CLI 再平衡减少 worker 数需等待一会儿才能在 Storm UI上显示,开始以为哪里出问题了。
- 用2台 supervisor测试,发现过2次两个 worker运行在同一个 supervisor 的情况,几十秒后又变成一个 supervisor 一个 worker了。
# k8s版 再平衡名称为 yee-topic-kafka-consumer 的拓扑,给此拓扑分配2个 worker kubectl exec -it yeenimbus-0 -- bash -c "storm rebalance yee-topic-kafka-consumer -n 2" # Docker版 再平衡名称为 yee-topic-kafka-consumer 的拓扑,给此拓扑分配2个 worker docker exec -it ebb bash -c "storm rebalance yee-topic-kafka-consumer -n 2" #-n : 调整的是 worker 的数量。 #-e : 调整的是Bolt, Spout 的 executor 数量。最多不能超过预先设定task的数量, 若设置为超过task 的数量,则executor数会调整为 task 的上限。 # K8S版 查看 storm 里运行拓扑的 worker、任务数 kubectl exec -it yeenimbus-0 -- bash -c "storm list" # Docker版 查看 storm 里运行拓扑的 worker、任务数 docker exec -it ebb bash -c "storm list"
5. K8S里添加一个 Storm UI 容器,开两台 supervisor 分析 Task 分布
(1)spout只在一台上运行问题:spout 4个task(spout-yeestorm-log-topic_TxId)平均分布在2台 supervisor,但始终1台在接受数据,这个问题后面会讲到是因为kafka使用了一个分区导致的。
(2)bolt只在一台上运行问题:Trident Stream上设置 parallelism hint 为4,但仅 spout 的 task 数变成了4,但处理数据的命中Bolt(b-1),task数还是1。对 Trident 链式设置 parallelism hint 语法理解有误导致的,改代码重新提交拓扑后,2台 supervisor 可以同时计算并命中日志。
6. 监视 Bolt 并发保存 mongodb 实体数据
(1)测试修改 syslogMatchIP,3台 supervisor 都追踪到了变化,但并发更新同一实体 OplogTimestampCommit timestamp 值时,1台上成功更新,其他两台报OptimisticLockingFailureException 错 但不影响使用。使用分布式锁或pipeline进程通信应该可解决先提个jira。
(2)单台 supervisor 里不用关心此问题有 ReentrantLock 保护是线程安全的。
7. 为何一个 supervisor 只跑了1个 worker 处理 topology?
几次测下来,从 Storm UI 发现个现象,就是拓扑设置了2个worker,必须开两个 supervisor 才能启动这两个worker,无法在一个 supervisor 里跑两个worker。
后来修改拓扑,把 spout task设为4,命中bolt task设为4,出现了两个worker都在一个supervisor运行的情况了,且命中功能正常。看来这不是问题。
8. 再平衡 Bolt
测试发现,再平衡策略命中的 Bolt,只会改 Executors 数,Tasks 数不会变。即使再平衡将此值设置的很高超过了拓扑中设置的 Tasks 数,最终平衡后,Executors 数也不会超过Tasks数。Bolt 的 Tasks数在 topology 代码中控制。
另外说明一下,由于项目使用 Trident API,spout名称和 bolt名称默认是自动生成的,目前是在每个 bolt 代码里打印日志才知道这些名称的。
# 给名为 yee-topic-kafka-consumer 的拓扑设置2个 worker,名为 b-1 的策略命中 bolt 设置4个 task kubectl exec -it yeenimbus-0 -- bash -c "storm rebalance yee-topic-kafka-consumer -n 2 -e b-1=4"
9. 延迟测试(重点)
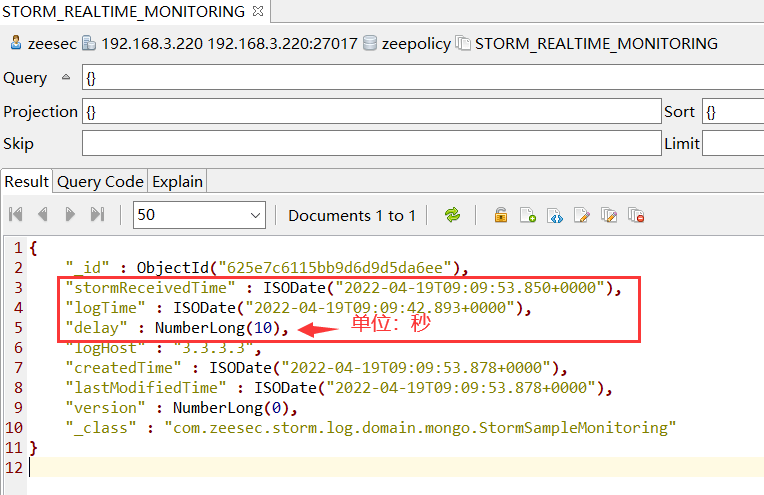
原理:在 topology 接收到正常数据的一刻(还未计算处理),插入一段代码,每隔10秒打印 storm服务器时间、日志时间、延迟时间(单位秒)到 mongodb 数据库中。这个延迟时间=”storm服务器时间 – 日志时间”,通过每隔10秒观察延迟变化就可以做一些决定性判断。
案例设计:1秒发1000条持续30秒,每隔10秒记录延迟情况到mongodb。
测试1:spout-task=1,hit-bolt-task=1:最后延迟达130秒
测试2:spout-task=1,hit-bolt-task=4:最后延迟达122秒
总结:延迟数随时间逐渐增大,增大 policy-hit bolt 的 task 数对缩小延迟功效甚微,问题的瓶颈在 spout 接收处!
每隔10秒 观察 mongodb 延迟数:
10 Kafka 分区设置
(1)从上面测试可看出,kafka消息积压,部署多个 spout 不能加快消费原有分区消息,查了下因为要保证 Partition 的读取顺序。
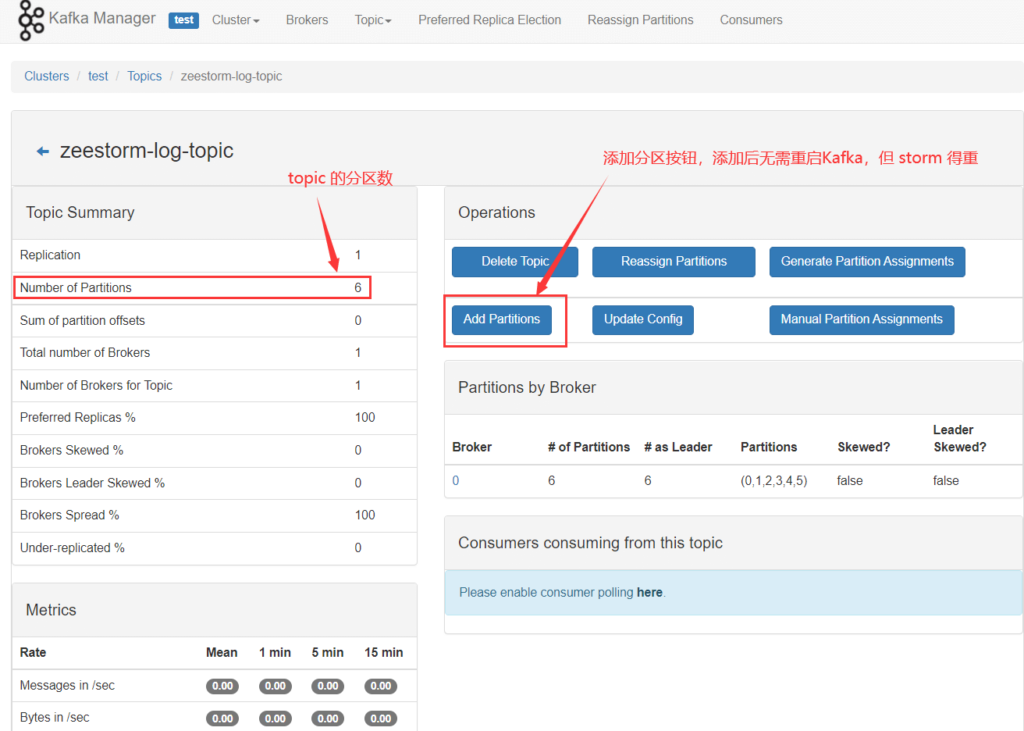
(2)增加分区,让进来的数据使用默认轮询策略平均分布到各分区上,这种方式明显解决了延迟问题。默认我们的 kafka 里 num.partitions=1,即 policy-hit topic 仅有一个分区,映射配置增加分区后重启也不管用,暂未找到原因,后来启动了 kafkamanager k8s容器,在UI上为 topic 成功添加了分区,应该也支持 shell 方式控制。
(3)动态调整分区
# 将 yeestorm-log-topic 这个 topic 调整到8个分区 kubectl exec -it yeekafka-0 -- bash -c "/opt/kafka/bin/kafka-topics.sh --alter --zookeeper yeezookeeper:2181 --topic yeestorm-log-topic --partitions 8"
(4)查看分区和副本
# 查看 yeestorm-log-topic 的分区数和副本数(ReplicationFactor): kubectl exec -it yeekafka-0 -- bash -c "/opt/kafka/bin/kafka-topics.sh --zookeeper yeezookeeper:2181 --topic yeestorm-log-topic --describe"
11. Kafka 多分区延迟测试,显著提高性能
案例设计:1 个kafka实例,对 policy-hit topic 分区测试,storm不去动它还是4个task平均分布在2台supervisor上,目前还是仅一个在拉取数据。1秒发1000条相同日志,持续30秒,总共3万条。
(1)1个Partition:最后延迟达122秒
(2)3个Partition,命中数1万:最后延迟达21秒
(3)6个Partition,命中数5千:最后延迟达4秒
测试发现,延迟随着 Partition 增加变短了,但命中数却越来越少,似乎 storm-kafka-client 仅在读老分区数据,这是比较理想的,因为这样其他分区就可以再用其他线程来读了,并行处理一个 topic 下的数据。重启 storm 发现解决了这个问题,6个Partition命中数接近 3 万,关键是延迟降到最大10秒(之前是122)。再去看两台 supervisor 的 worker 日志,都已经各自在拉取数据了!
总结:通过单个 kafka 增加分区可以让 kafka的消费者(storm)并行处理,只需增加 spout task数。增加分区后得重启 storm 以便并行拉取数据。
12. Storm UI 和 KafkaManager UI 截图
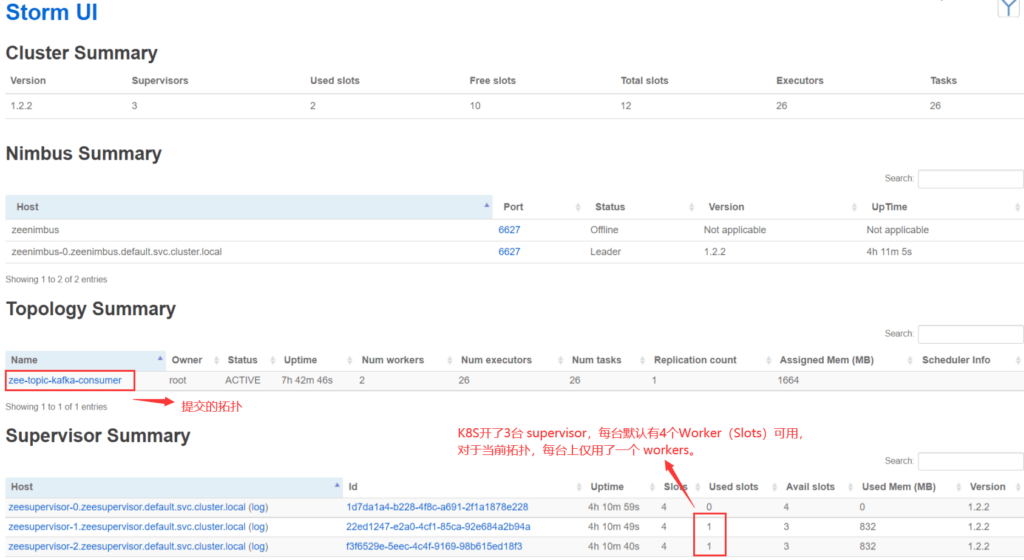
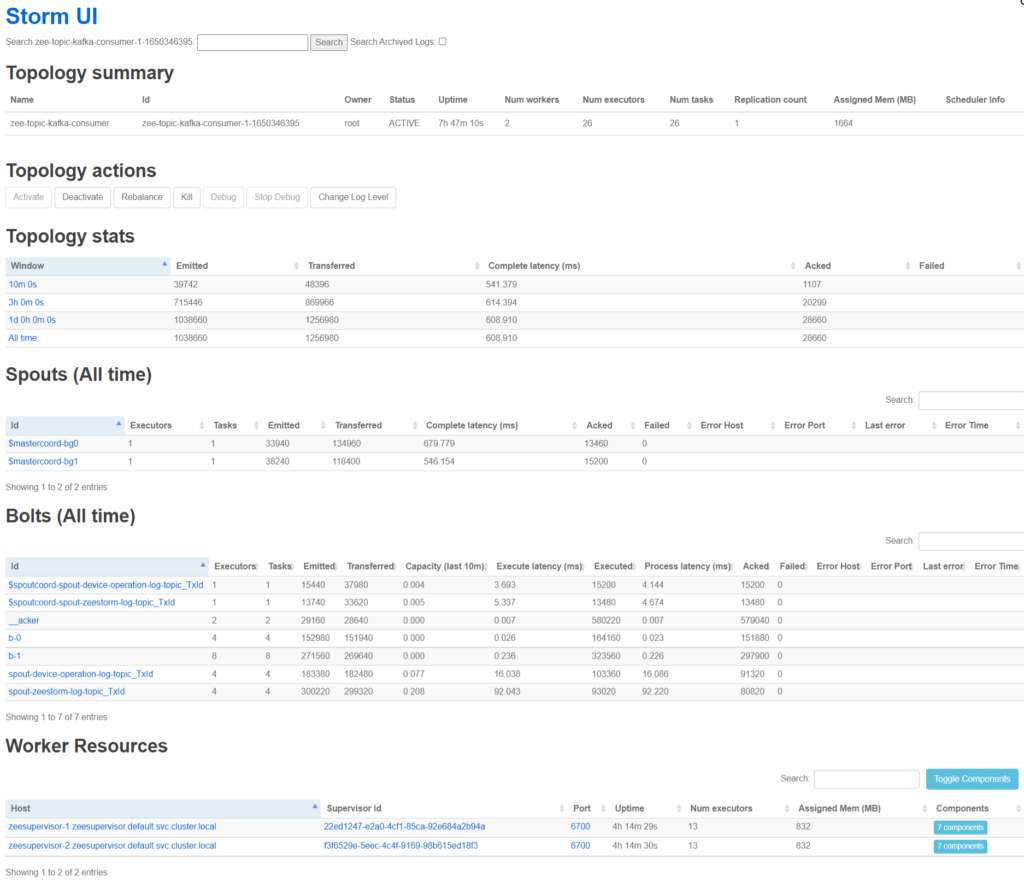
Storm UI 对于分析 Storm 的 Executors 和 Tasks 在 Workers 中的分布非常直观,强烈推荐!
(1)Storm集群视角
(2)Supervisor 视角看 worker Bolt组件的 Task数
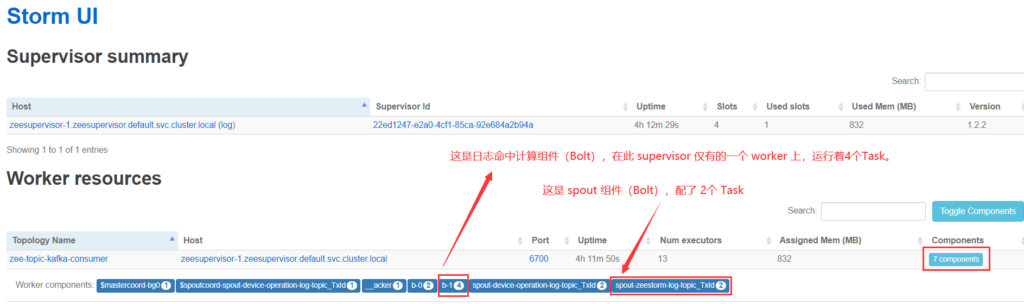
(3)Bolt组件视角看task数
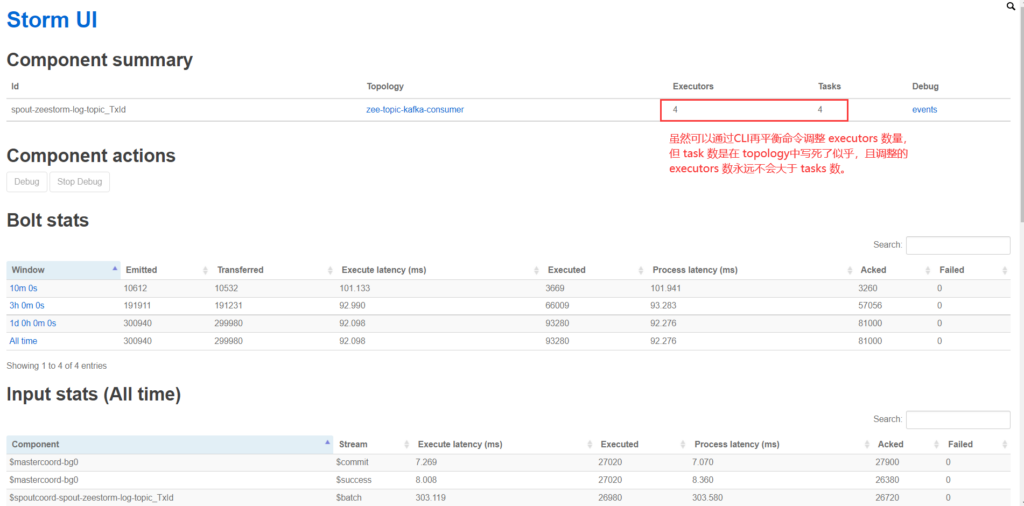
(4)拓扑视角
(5)KafkaManager 分区添加