ElasticSearch 8.7 开始支持时序数据(TSDS)和降采样(Downsampling)。对时间序列数据流(TSDS)进行降采样的推荐方法是使用索引生命周期管理(ILM),也可以手动调用 降采样API 来触发降采样。
TSDS与常规数据流的区别
- 索引模板要设置 index.mode: time_series
- 除了要有 @timestamp,还要至少一个 keyword 类型的维度(dimension)字段,以及至少一个指标(metric)字段
- Elastic 会为 TSDS 中的每个文档生成一个隐藏的 _tsid 元数据字段,_tsid 是一个包含 dimension 的对象,同一 TSDS 中具有相同 _tsid 的文档是同一时间序列的一部分。
- TSDS 使用 “time-bound backing indices” 将同一时间段的数据存储在同一后备索引中。
- (TSDS 的索引模板必须包含 index.routing_path 设置,TSDS 使用此设置来执行基于维度的路由(dimension-based routing)。
- TSDS 使用内部的 “index sorting”按 _tsid 和 @timestamp 对分片段进行排序。
- TSDS document 仅支持自动生成的文档 _id 值,不支持自定义文档 _id 值。对于 TSDS 文档,文档 _id 是文档维度和 @timestamp 的哈希值。
- TSDS 使用 “synthetic _source”,因此受到许多限制,合成的 _source 限制请参考:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-source-field.html#synthetic-source-restrictions
- TSDS 可以包含维度或指标以外的字段
官方参考(重要):https://www.elastic.co/guide/en/elasticsearch/reference/current/tsds.html#differences-from-regular-data-stream
官方案例:https://www.elastic.co/guide/en/elasticsearch/reference/current/use-elasticsearch-for-time-series-data.html
TSDS 的定义
创建组件模板
需要定义维度(dimension)、指标(metric)字段:
{
"template": {
"mappings": {
"properties": {
"@timestamp": {
"type": "date",
"format": "date_optional_time||epoch_millis"
},
"ruleUuid": {
"type": "keyword",
"time_series_dimension": true
},
"hostIP": {
"type": "keyword",
"time_series_dimension": true
},
"hitCount": {
"type": "long",
"time_series_metric": "gauge"
}
}
}
}
}
注意:text 类型不支持定义维度字段,可以定义维度字段的类型参考:Time series data stream (TSDS)
创建索引模板
专门针对时序数据定义的索引模板,这里使用生命周期自动管理时序数据:
{
"index_patterns": [
"my-policy-log*"
],
"data_stream": {},
"template": {
"settings": {
"index": {
"mode": "time_series",
"look_ahead_time": "1m",
"number_of_replicas": 0,
"number_of_shards": 2
},
"index.lifecycle.name": "my-policy-log"
}
},
"composed_of": [
"my-policy-log"
],
"priority": 101
}
创建生命周期策略
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_age": "5m"
},
"downsample": {
"fixed_interval": "1h"
}
}
}
}
}
}
上面的配置,每隔5分钟进行索引翻转,fixed_interval 表示将1小时内的数据汇聚起来以减少数据量,不是每隔1小时触发一次。
自动降采样
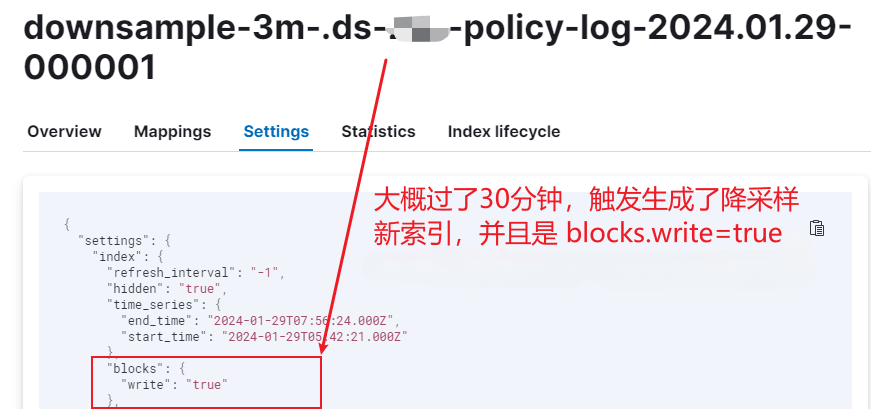
DownSample操作是对一个原始索引执行DownSample,生成DownSample索引。DownSample操作是在索引rollover后产生了一个新索引,然后旧索引过了一段时间,不再写入数据时进行的。目前默认是当前时间比旧索引的end_time大两小时才开始进行DownSample。为了模拟这个效果,创建索引时可以手动指定start_time和end_time。参考阿里文档。
重要提醒:最新索引的end_time会被Elasticsearch修改为最新时间,影响DownSample演示,默认是5分钟修改一次。DownSample演示操作要确保end_time不被修改,end_time值可通过GET {index}/_settings命令查看。
自动降采样 – ILM
手动降采样时,给滚动索引设置了 index.blocks.write = true(用ILM不需要设置),此时索引的当前 action 变成 downsample 了,且有告警:
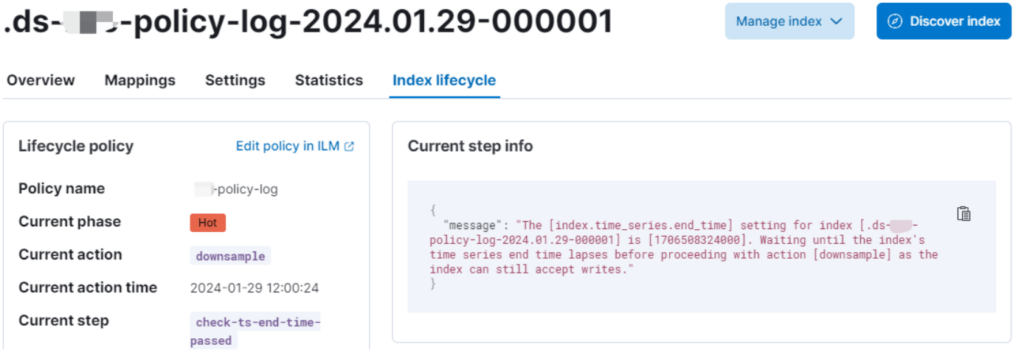
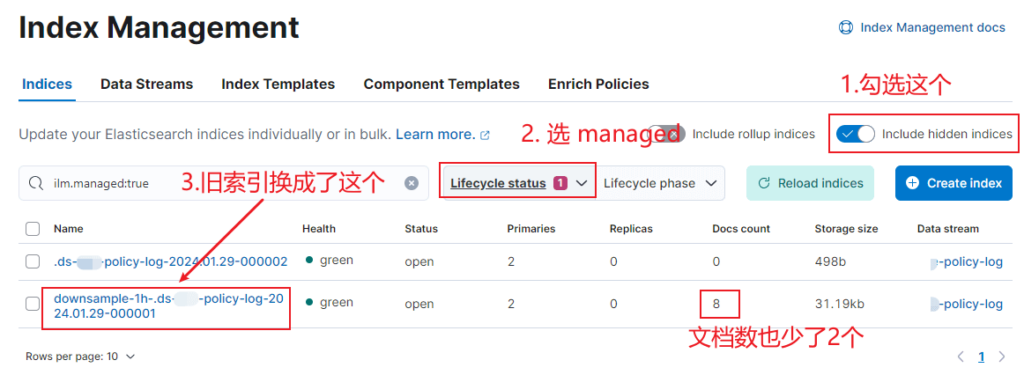
似乎看到希望了,时间来到 index.time_series.end_time 还是没有自动触发降采样,直到再过5分钟左右终于看到原来的滚动索引 .ds-my-policy-log-2024.01.29-000001 变成了 downsample-1h-.ds-my-policy-log-2024.01.29-000001,名字多了前缀 downsample-1h-,文档数也少了2条:
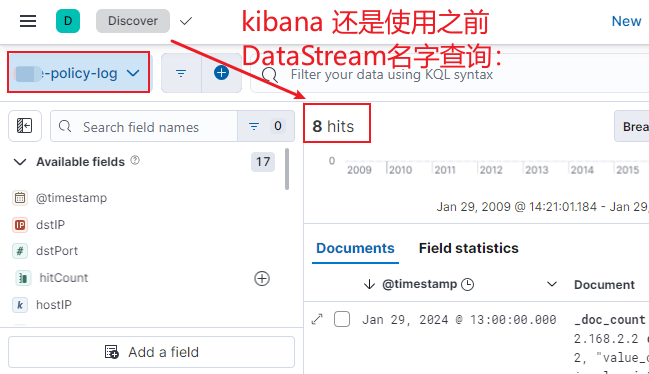
降采样后,数据也查到了:
看来配置是没有问题的,只是等的太久了,具体要等多久,目前心理也没数何时会触发。索引生命周期管理检查符合策略标准的索引的频率默认是10分钟检查一次:indices.lifecycle.poll_interval。
自动降采样 – 索引区间
Elasticsearch 在索引创建和翻转过程中自动配置 index.time_series.start_time 和 index.time_series.end_time值,但通过设置 index.look_ahead_time 可以控制 index.time_series.end_time 值的生成,默认是按: now + index.look_ahead_time。
在时间序列轮询间隔(通过 time_series.poll_interval 设置控制),Elasticsearch 检查 write index 是否满足其索引生命周期策略中的滚动条件,如果不满足,Elasticsearch 会刷新当前值并将 write index 的 index.time_series.end_time 更新为:now + index.look_ahead_time + time_series.poll_interval。此过程将持续到 write index 翻转为止。当索引滚动时,Elasticsearch 为索引设置最终的 index.time_series.end_time 值。
只有当插入数据的 @timestamp 时间字段值落在 start_time 和 end_time 之间才能被索引。
与降采样的关系,我的理解:到达 end_time 后才会触发降采样,降采样过程中会经历多个 step,要登上好多分钟。参考 time-bound-indices:
Some ILM actions mark the source index as read-only, or expect the index to not be actively written anymore in order to provide good performance. These actions are: – Delete – Downsample – Force merge – Read only – Searchable snapshot – Shrink Index lifecycle management will not proceed with executing these actions until the upper time-bound for accepting writes, represented by the index.time_series.end_time index setting, has lapsed.
look_ahead_time 参数默认是 2h(2小时),但 end_time 的计算似乎有个固定的 2h(有点困惑,有时候又没有,未理解透),因此默认生成的索引 start_time和end_time间隔了4小时,如果设置 look_ahead_time 为1m(1分钟),start_time和end_time就间隔2小时1分钟:
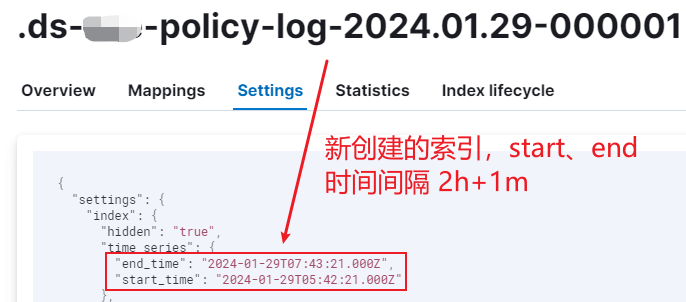
此时索引的 action 和 step:
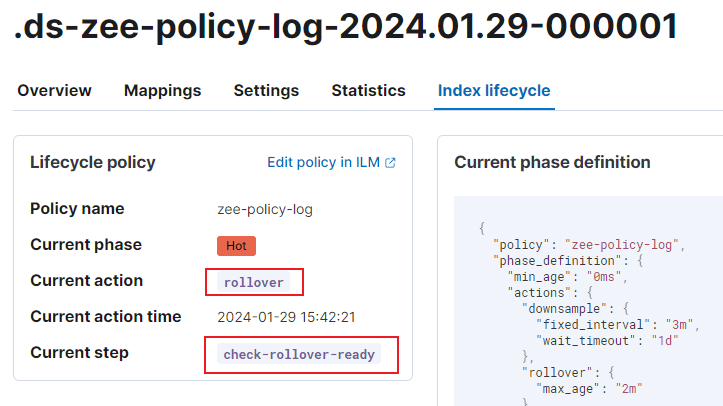
降采样阶段先看到了这个 wait-for-shard-history-leases:
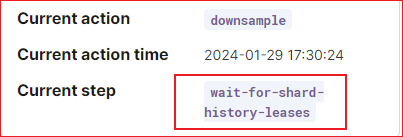
然后变为 check-ts-end-time-passed:
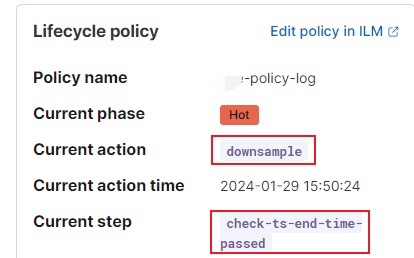
最后触发了降采样:
降采样后 gauge 类型的指标字段(使用 counter 计数器类型汇聚后无法进行 sum),不是一个数字了,变成了一个对象。
java上处理的时候要特别小心,对于还没汇聚的 hitCount值是一个整数,对于已汇聚的是一个 LinkedHashMap类型:

降采样后新的时间戳问题
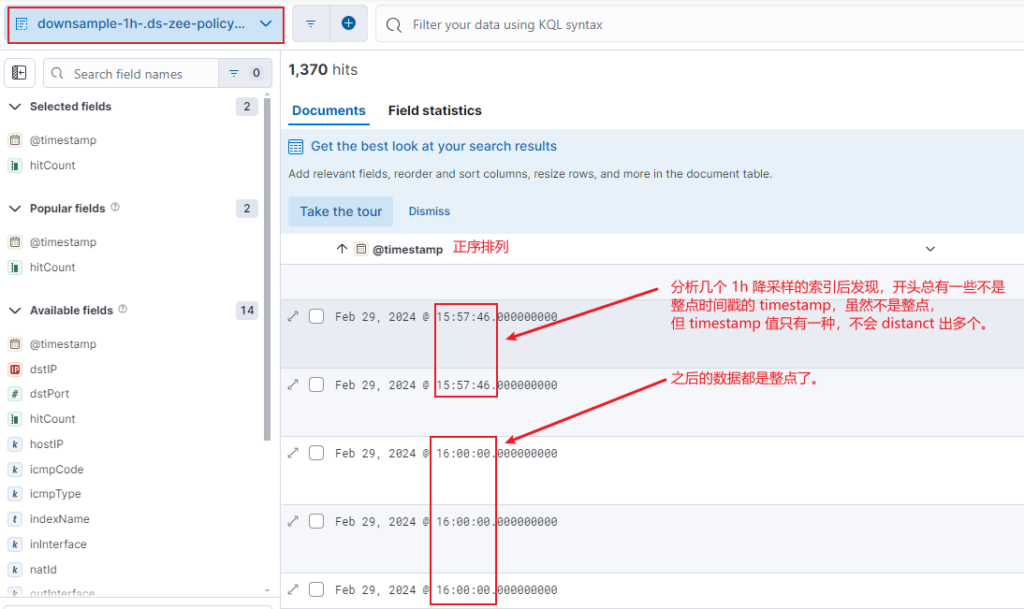
降采样测试
北京时间 8-31 13:37 分创建一条时序索引,三天后再来看。
先来看降采样配置:
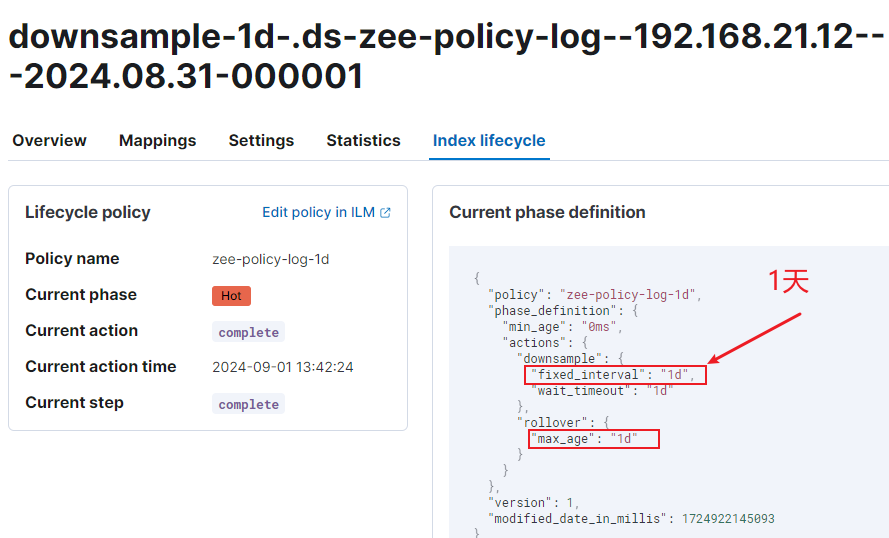
再看这条 08:31日索引的 startTime:
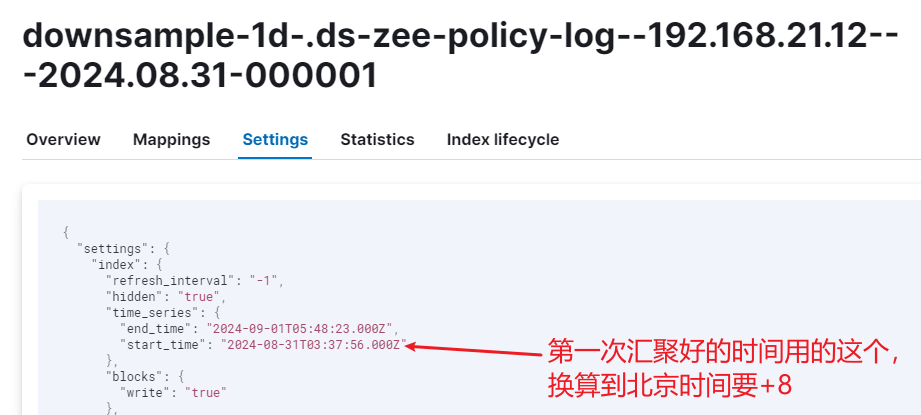
上面可以看到,时序索引的创建时间是 8-31 13:37,但是降采样生成的这条索引的 start_time却比创建的时间还早,正好向前推了2小时,这与 index.look_ahead_time 有关,这个值范围是1分钟到2小时。
此外,降采样的结果里发现了两个时间点的降采样数据:
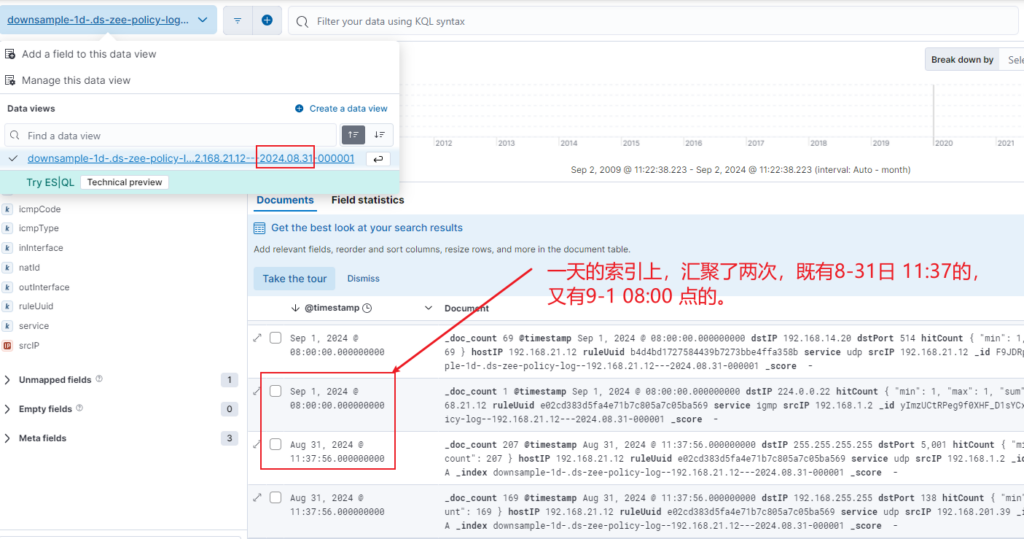
后续观察 09.01 的降采样索引内容,发现还是降采样里有两个时间点的数据:

两个汇聚的时间点的数据而且有重复的,这个我猜与 创建索引的时间段有关,你看 start_time和end_time就跨越了两天:
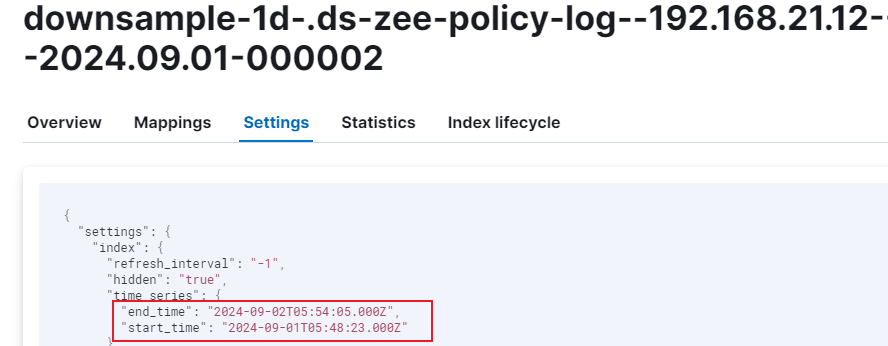
通过临时调整 Linux 宿主机时间来触发降采样
以下是一个10天后进行 rollover 并立即(min_age 设为0了)进入 warm 阶段的生成周期策略配置:
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_age": "10d"
}
}
},
"warm": {
"min_age": "0d",
"actions": {
"downsample": {
"fixed_interval": "1d"
}
}
},
"delete": {
"min_age": "365d",
"actions": {
"delete": {}
}
}
}
}
}
若使用的是 elasticsearch docker容器,想立即测试降采样,可先关闭容器 临时调快宿主机的时间,调整命令:date -s “20241209 19:55:00”,然后重启容器。此时你会发现大概几分钟后会开始降采样了。降采样阶段步骤 wait-for-shard-history-leases、check-ts-end-time-passed 分别需要几分钟完成,预估20分钟内完成。
若没有触发降采样,可以检查下索引的年龄是否超过了10天,命令:GET <index_name>/_ilm/explain ,对应返回结果里的 age 字段值。
min_age: 10d 意味着索引必须达到 10 天的年龄才会从 hot 阶段切换到 warm 阶段。如果 hot 阶段的 rollover 条件也设置为 10d,可能导致索引进入 warm 阶段的时间进一步延迟,因为 rollover 生成的新索引从其创建时开始计时 min_age,因此新索引实际进入 warm 阶段的时间是 rollover 的触发时间加上 10d。
例如:hot 阶段的 rollover 设置为 max_age: 10d,warm 阶段的 min_age: 10d,在这种情况下,warm 阶段的切换时间实际可能是 10d + 10d = 20d。为确保 rollover 和 warm 的时间逻辑一致。可以将 warm 阶段的 min_age 设置为 0d 或更小值,从 rollover 切换时立即进入 warm 阶段。
再次强调,ILM 中每一个新阶段(Phase)的 min_age 计时器,都是在上一个阶段完成后才开始重新计算的,因此下面的ILM代表30天后删除数据:
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_age": "10d"
}
}
},
"warm": {
"min_age": "0ms",
"actions": {
"downsample": {
"fixed_interval": "1d"
}
}
},
"delete": {
"min_age": "20d",
"actions": {
"delete": {}
}
}
}
}
}
手动降采样
介绍
降采样使用UTC时间戳。
手动降采样可直接参考官方 Data streams 的 Run downsampling manually,一路 Copy 到 Kibana 来测很方便。创建索引时可手动指定 start_time 和 end_time,参考 TimeStream管理Elasticsearch时序数据快速入门。流程步骤:
- 创建一个时序 Data Stream
- 摄入时间序列数据
- 执行 TSDS 降采样
手动降采样后旧索引不会自动删除(ILM会自动删),因此还可以继续往旧索引里插入数据来测试,但得先取消只读 "index.blocks.write": "false" 后才能往里插数据,调用接口:
PUT /.ds-my-data-stream-2024.09.23-000001/_settings
{
"index.blocks.write": "false"
}
设置好后,回头复制官网代码再插入10条数据成功。
Demo
下面是直接拷贝的 Run downsampling manually 的测试Demo,大部分都一样,只有在创建时序DataStream 时加了 start_time 和 end_time:
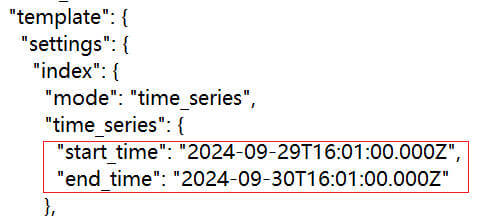
第一步:创建时序DataStream
PUT _index_template/my-data-stream-template
{
"index_patterns": [
"my-data-stream*"
],
"data_stream": {},
"template": {
"settings": {
"index": {
"mode": "time_series",
"time_series": {
"start_time": "2024-09-29T16:01:00.000Z",
"end_time": "2024-09-30T16:01:00.000Z"
},
"routing_path": [
"kubernetes.namespace",
"kubernetes.host",
"kubernetes.node",
"kubernetes.pod"
],
"number_of_replicas": 0,
"number_of_shards": 2
}
},
"mappings": {
"properties": {
"@timestamp": {
"type": "date"
},
"kubernetes": {
"properties": {
"container": {
"properties": {
"cpu": {
"properties": {
"usage": {
"properties": {
"core": {
"properties": {
"ns": {
"type": "long"
}
}
},
"limit": {
"properties": {
"pct": {
"type": "float"
}
}
},
"nanocores": {
"type": "long",
"time_series_metric": "gauge"
},
"node": {
"properties": {
"pct": {
"type": "float"
}
}
}
}
}
}
},
"memory": {
"properties": {
"available": {
"properties": {
"bytes": {
"type": "long",
"time_series_metric": "gauge"
}
}
},
"majorpagefaults": {
"type": "long"
},
"pagefaults": {
"type": "long",
"time_series_metric": "gauge"
},
"rss": {
"properties": {
"bytes": {
"type": "long",
"time_series_metric": "gauge"
}
}
},
"usage": {
"properties": {
"bytes": {
"type": "long",
"time_series_metric": "gauge"
},
"limit": {
"properties": {
"pct": {
"type": "float"
}
}
},
"node": {
"properties": {
"pct": {
"type": "float"
}
}
}
}
},
"workingset": {
"properties": {
"bytes": {
"type": "long",
"time_series_metric": "gauge"
}
}
}
}
},
"name": {
"type": "keyword"
},
"start_time": {
"type": "date"
}
}
},
"host": {
"type": "keyword",
"time_series_dimension": true
},
"namespace": {
"type": "keyword",
"time_series_dimension": true
},
"node": {
"type": "keyword",
"time_series_dimension": true
},
"pod": {
"type": "keyword",
"time_series_dimension": true
}
}
}
}
}
}
}
第二步:摄入时间序列数据
PUT _ingest/pipeline/my-timestamp-pipeline
{
"description": "Shifts the @timestamp to the last 15 minutes",
"processors": [
{
"set": {
"field": "ingest_time",
"value": "{{_ingest.timestamp}}"
}
},
{
"script": {
"lang": "painless",
"source": """
def delta = ChronoUnit.SECONDS.between(
ZonedDateTime.parse("2022-06-21T15:49:00Z"),
ZonedDateTime.parse(ctx["ingest_time"])
);
ctx["@timestamp"] = ZonedDateTime.parse(ctx["@timestamp"]).plus(delta,ChronoUnit.SECONDS).toString();
"""
}
}
]
}
PUT /my-data-stream/_bulk?refresh&pipeline=my-timestamp-pipeline
{"create": {}}
{"@timestamp":"2022-06-21T15:49:00Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":91153,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":463314616},"usage":{"bytes":307007078,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":585236},"rss":{"bytes":102728},"pagefaults":120901,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}
{"create": {}}
{"@timestamp":"2022-06-21T15:45:50Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":124501,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":982546514},"usage":{"bytes":360035574,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":1339884},"rss":{"bytes":381174},"pagefaults":178473,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}
{"create": {}}
{"@timestamp":"2022-06-21T15:44:50Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":38907,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":862723768},"usage":{"bytes":379572388,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":431227},"rss":{"bytes":386580},"pagefaults":233166,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}
{"create": {}}
{"@timestamp":"2022-06-21T15:44:40Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":86706,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":567160996},"usage":{"bytes":103266017,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":1724908},"rss":{"bytes":105431},"pagefaults":233166,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}
{"create": {}}
{"@timestamp":"2022-06-21T15:44:00Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":150069,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":639054643},"usage":{"bytes":265142477,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":1786511},"rss":{"bytes":189235},"pagefaults":138172,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}
{"create": {}}
{"@timestamp":"2022-06-21T15:42:40Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":82260,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":854735585},"usage":{"bytes":309798052,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":924058},"rss":{"bytes":110838},"pagefaults":259073,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}
{"create": {}}
{"@timestamp":"2022-06-21T15:42:10Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":153404,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":279586406},"usage":{"bytes":214904955,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":1047265},"rss":{"bytes":91914},"pagefaults":302252,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}
{"create": {}}
{"@timestamp":"2022-06-21T15:40:20Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":125613,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":822782853},"usage":{"bytes":100475044,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":2109932},"rss":{"bytes":278446},"pagefaults":74843,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}
{"create": {}}
{"@timestamp":"2022-06-21T15:40:10Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":100046,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":567160996},"usage":{"bytes":362826547,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":1986724},"rss":{"bytes":402801},"pagefaults":296495,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}
{"create": {}}
{"@timestamp":"2022-06-21T15:38:30Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":40018,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":1062428344},"usage":{"bytes":265142477,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":2294743},"rss":{"bytes":340623},"pagefaults":224530,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}
GET /my-data-stream/_search
第三步:降采样
(1)降采样仅用于 TSDS 的后备索引,可以通过此接口查看后备索引(在 indices 属性上):
GET /_data_stream/my-data-stream
(2)滚动(Rollover)TSDS
POST /my-data-stream/_rollover/
重要提醒:由于索引模板上已固定了 start_time 和 end_time,滚动创建的新后备索引的 start_time 和 end_time 也会用这固定的,导致报错:backing index [xxx-01] with range [aaa] is overlapping with backing index [xxx-02] with range [aaa]”。因此调用滚动API前需要更新索引模板的 start_time 和 end_time。
(3)被降采样的索引设置 read-only 模式:
PUT /.ds-my-data-stream-2024.09.30-000001/_block/write
(4)执行降采样:
POST /.ds-my-data-stream-2024.09.30-000001/_downsample/.ds-my-data-stream-2023.07.26-000001-downsample
{
"fixed_interval": "1d"
}
提醒:手动降采样生成的新索引,不会自动关联到 data-stream,需要手动设置。
(5)修改 Data Stream,替换旧索引为新索引:
POST _data_stream/_modify
{
"actions": [
{
"remove_backing_index": {
"data_stream": "my-data-stream",
"index": ".ds-my-data-stream-2024.09.30-000001"
}
},
{
"add_backing_index": {
"data_stream": "my-data-stream",
"index": ".ds-my-data-stream-2023.07.26-000001-downsample"
}
}
]
}
(6)删除旧的索引:
DELETE /.ds-my-data-stream-2024.09.30-000001
警告:这会删除原始数据,若需要保留可不删
(7)查看结果:
GET /my-data-stream/_search
接收早于指定时间的 @timestamp 文档
控制索引2小时以前的数据可以试用 index.look_back_time 参数,此参数默认就是2小时,参考:https://www.elastic.co/guide/en/elasticsearch/reference/current/tsds.html#tsds-look-back-time
快照生命周期管理 (SLM)
略
Rollup Jobs
Rollups 已弃用并将在后续版本中移除。请改用 downsampling。
添加新字段
首先要给组件模板添加新字段,但是它不会应用于当前时序数据的写入索引。测试发现,当往旧索引插入新字段数据时,默认会创建一个 text 字段类型,只是类型不是 keyword 导致排序查询报错了,那么灵感来了。
ElasticSearch支持给现有索引添加新字段,但不能修改已有字段的类型。我的项目使用时序数据,索引查询的是逻辑层面的 DataSteam,为了得到当前数据流的写入索引来添加字段,需要先查询”GET _data_stream/your_datastream_name”,有了写入索引,就可以给它添加新字段了(用接口 PUT .ds-your_datastream_name-2024.02.06-000001/_mapping)。配合排序搜索时设置 unmappedType(FieldType.Keyword) 可以完美解决升级新字段带来的问题。
新增的字段不能加 time_series_dimension,time_series_dimension 必须在索引创建时定义,不能后期修改(也就是说当前写索引是不能加 time_series_dimension了,但基于新模板创建的新索引是有此属性的)。测下来不影响使用,但如果要对新字段进行聚合查询最好加这个属性,此时只能 Reindex 迁移数据。
注意点
时间戳可以一样,只需维度不一样
