1 Storm安装与启动
分布式实时计算框架,比较主流的有 Storm、Spark和 Flink。
1.1 以下是安装 Storm 的步骤概要
- 安装 ZooKeeper 集群(kafka已自带);
- 在各个机器上安装运行集群所需要的依赖组件;
- 下载 Storm 安装程序并解压缩到集群的各个机器上;
- 在 storm.yaml 中添加集群配置信息;
- 使用 “storm” 脚本启动各机器后台进程。
storm下载地址:http://storm.apache.org/downloads.html
配置项默认值:https://github.com/apache/storm/blob/master/conf/defaults.yaml
注:storm.yaml会覆盖 defaults.yaml中各个配置项的默认值。
1.2 集群方式启动
最后一步是启动所有的 Storm 后台进程。注意,这些进程必须在严格监控下运行。因为 Storm 是个与 ZooKeeper 相似的快速失败系统,其进程很容易被各种异常错误终止。之所以设计成这种模式,是为了确保 Storm 进程可以在任何时刻安全地停止并且在进程重新启动之后恢复征程。这也是 Storm 不在处理过程中保存任何状态的原因 —— 在这种情况下,如果有 Nimbus 或者 Supervisor 重新启动,运行中的拓扑不会受到任何影响。下面是启动后台进程的方法:
- Nimbus:在 master 机器上,执行下面的命令。
$ bin/storm nimbus
- Supervisor:在每个工作节点上,在监控下执行下面命令。Supervisor 的后台进程主要负责启动/停止该机器上的 worker 进程。
$ bin/storm supervisor
- UI:在 master 机器上,在监控下执行下面命令启动 Storm UI(Storm UI 是一个可以在浏览器中方便地监控集群与拓扑运行状况的站点)后台进程。可以通过 http://{nimbus.host}:8080 来访问 UI 站点。
$ bin/storm ui
1.3 提交拓扑
$ mvn clean package -P prod $ ./bin/storm jar /home/admin/dev/storm/falstorm-log-0.0.4-SNAPSHOT.jar org.springframework.boot.loader.JarLauncher prod
注:最后的 prod是我自己定义的参数,传入main函数后,用来选择使用localSubmitter还是StormSubmitter提交拓扑。
2 Storm 消息机制
2.1 Storm的计算语义
- at-most-once:spout针对相同的tuple只发送一次即可,不需要实现fail和ack方法。
- at-least-once:是用acker机制实现的,我们需要实现spout的两个方法:fail和ack,在topology上增加一个ackerbolt,spout和bolt发出的每一个tuple都会被将跟踪信息写到ackerbolt,如果这个tuple正常被处理,则调用spout的ack方法,否则调用fail方法。
- exactly-once:恰好一次处理,使用storm的高级部分trident实现。batch作为一个transaction的单位,一个batch包含多个tuple,transaction分成两个部分:processing和commit,processing阶段并行执行,commit阶段严格按序提交transaction状态数据到zk,在transaction的任一阶段出现问题,都会将该事务的结果扔掉,spout重发该事务的batch数据。
2.2 Topology
Storm 的拓扑是对实时计算应用逻辑的封装,它的作用与 MapReduce 的任务(Job)很相似,区别在于 MapReduce 的一个 Job 在得到结果之后总会结束,而拓扑会一直在集群中运行,直到你手动去终止它。拓扑还可以理解成由一系列通过数据流(Stream Grouping)相互关联的 Spout 和 Bolt 组成的的拓扑结构。Spout 和 Bolt 称为拓扑的组件(Component)。
2.3 可靠性保证
Storm 可以通过拓扑来确保每个发送的元组都能得到正确处理。通过跟踪由 Spout 发出的每个元组构成的元组树可以确定元组是否已经完成处理。每个拓扑都有一个“消息延时”参数,如果 Storm 在延时时间内没有检测到元组是否处理完成,就会将该元组标记为处理失败,并会在稍后重新发送该元组。
2.4 Metrics Collector
Storm提供了一个 Metrics Collector,将搜集到的度量等数据存储到 Influxdb,这个搜集器可以用于单个Topology上,也可以用于Storm Cluster上。
3 Trident
Trident 一个很酷的特性就是它支持完全容错性和恰好一次处理的语义。如果处理过程中出现错误需要重新执行处理操作,Trident 不会向数据库中提交多次来自相同的源数据的更新操作,这就是 Trident 持久化 state 的方式。
Trident 让实时计算变得非常简单。你已经看到了高吞吐量的数据流处理、状态操作以及低延时查询处理是怎样通过 Trident 的 API 来实现无缝结合的。总而言之,Trident 可以让你以一种更加自然,同时仍然保持着很好的性能的方式实现实时计算。
关于配置 Storm + Trident 的建议:worker 的数量最好是服务器数量的倍数;topology 的总并发度(parallelism)最好是 worker 数量的倍数;Kafka 的分区数(partitions)最好是 Spout(特指 KafkaSpout)并发度的倍数。
3.1 Trident State
Trident 中含有对状态化(stateful)的数据源进行读取和写入操作的一级抽象封装工具。这个所谓的状态(state)既可以保存在拓扑内部(保存在内存中并通过 HDFS 来实现备份),也可以存入像 Memcached 或者 Cassandra 这样的外部数据库中。而对于 Trident API 而言,这两种机制并没有任何区别。
你可以使用任何一种你想要的方法来实现 state 的存储操作。你可以把 state 存入外部数据库,也可以保存在内存中然后在存入 HDFS 中(有点像 HBase 的工作机制)。State 也并不需要一直保存某个状态值。比如,你可以实现一个只保存过去几个小时数据并将其余的数据删除的 State。这是一个实现 State 的例子:Memcached integration。
记住一点,Trident 是通过小数据块(batch)的方式来处理 tuple 的,而且每个 batch 都会有一个唯一的 txid。spout 的特性是由他们所提供的容错性保证机制决定的,而且这种机制也会对每个 batch 发生作用。
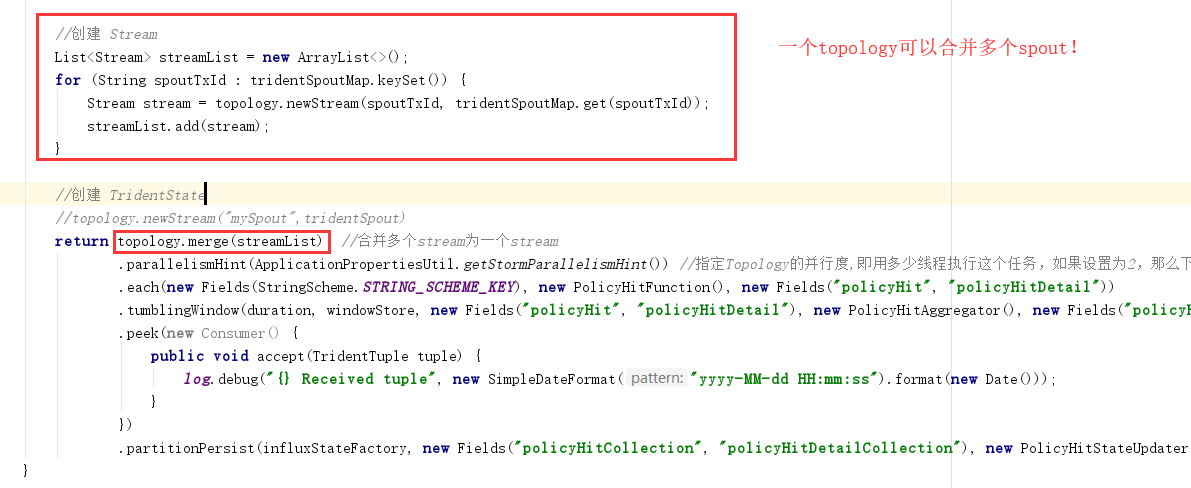
3.2 一个Topology使用多个Spout或多个Stream
这里我们使用 topology.merge() 来合并多个 stream。
3.3 Trident 拓扑可以设计成条件路径(if-else)的工作流形式
bolt 在接收 spout 的数据流时,可以根据输入 tuple 的值来选择将数据流发送到 bolt1 或者 bolt2,而不是同时向两个 bolt 发送。那么使用Trident后,也可以实现类似功能,Trident 的 each运算符可以返回一个数据流对象,你可以将该对象存储在某个变量中,然后你可以对同一个数据流执行多个 each 操作来分解该数据流,如下述代码所示:
Stream s = topology.each(...).groupBy(...).aggregate(...) Stream branch1 = s.each(..., FilterA) Stream branch2 = s.each(..., FilterB)
你可以使用 join、merge 或者 multiReduce 来联结各个数据流。
到目前为止,Trident 暂时不支持输出多个数据流。
4 Spout
Spout是拓扑中数据流的来源。根据需求的不同,Spout 既可以定义为可靠的数据源,也可以定义为不可靠的数据源。
一个 Spout 可以发送多个数据流。为了实现这个功能,可以先通过 OutputFieldsDeclarer 的 declareStream 方法来声明定义不同的数据流,然后在发送数据时在 SpoutOutputCollector 的 emit 方法中将数据流 id 作为参数来实现数据发送的功能。
Spout 中的关键方法是 nextTuple。需要特别注意的是,由于 Storm 是在同一个线程中调用所有的 Spout 方法,nextTuple 不能被 Spout 的任何其他功能方法所阻塞,否则会直接导致数据流的中断(关于这一点,阿里的 JStorm 修改了 Spout 的模型,使用不同的线程来处理消息的发送,这种做法有利有弊,好处在于可以更加灵活地实现 Spout,坏处在于系统的调度模型更加复杂,如何取舍还是要看具体的需求场景吧——译者注)。
Spout 中另外两个关键方法是 ack 和 fail,他们分别用于在 Storm 检测到一个发送过的元组已经被成功处理或处理失败后的进一步处理。注意,ack 和 fail 方法仅仅对“可靠的” Spout 有效。
事务型 spout(Transactional spouts)
看到这里,你可能会有这样的疑问:为什么不在拓扑中完全使用事务型 spout 呢?这个原因很好理解。一方面,有些时候事务型 spout 并不能提供足够可靠的容错性保障,所以不需要使用事务型 spout。比如,TransactionalTridentKafkaSpout 的工作方式就是使得带有某个 txid 的 batch 中包含有来自一个 Kafka topic 的所有 partition 的 tuple。一旦一个 batch 被发送出去,在将来无论重新发送这个 batch 多少次,batch 中都会包含有完全相同的 tuple 集,这是由事务型 spout 的语义决定的。现在假设 TransactionalTridentKafkaSpout 发送出的某个 batch 处理失败了,而与此同时,Kafka 的某个节点因为故障下线了。这时你就无法重新处理之前的 batch 了(因为 Kafka 的节点故障,Kafka topic 必然有一部分 partition 无法获取到),这个处理过程也会因此终止。
这就是要有“模糊事务型” spout 的原因了 —— 模糊事务型 spout 支持在数据源节点丢失的情况下仍然可以实现恰好一次的处理语义。
顺便提一点,如果 Kafka 支持数据复制,那么就可以放心地使用事务型 spout 提供的容错性机制了,因为这种情况下某个节点的故障不会导致数据丢失,不过 Kafka 暂时还不支持该特性。
5 Bolt
Bolt是数据流处理组件,拓扑中所有的数据处理均是由 Bolt 完成的。通过数据过滤(filtering)、函数处理(functions)、聚合(aggregations)、联结(joins)、数据库交互等功能,Bolt 几乎能够完成任何一种数据处理需求。一个 Bolt 可以实现简单的数据流转换,而更复杂的数据流变换通常需要使用多个 Bolt 并通过多个步骤完成。
与 Spout 相同,Bolt 也可以输出多个数据流。为了实现这个功能,可以先通过 OutputFieldsDeclarer 的 declareStream 方法来声明定义不同的数据流,然后在发送数据时在 OutputCollector 的 emit 方法中将数据流 id 作为参数来实现数据发送的功能。
Bolt 的关键方法是 execute方法。execute 方法负责接收一个元组作为输入,并且使用 OutputCollector 对象发送新的元组。如果有消息可靠性保障的需求,Bolt 必须为它所处理的每个元组调用 OutputCollector 的 ack 方法,以便 Storm 能够了解元组是否处理完成(并且最终决定是否可以响应最初的 Spout 输出元组树)。一般情况下,对于每个输入元组,在处理之后可以根据需要选择不发送还是发送多个新元组,然后再响应(ack)输入元组。IBasicBolt 接口能够实现元组的自动应答。
请注意 OutputCollector 不是线程安全的对象,所有的 emit、ack 和 fail 操作都需要在同一个线程中进行处理。
Stream grouping
为拓扑中的每个 Bolt 的确定输入数据流是定义一个拓扑的重要环节。数据流分组定义了在 Bolt 的不同任务(tasks)中划分数据流的方式。在 Storm 中有八种内置的数据流分组方式。
6 storm 默认配置
7 storm源码BUG处理
如果你像我一样使用的是 storm-1.2.2版本,那么在使用 KafkaTridentSpoutOpaque 时会遇到一个BUG:当设置Kafka的 FirstPollOffsetStrategy策略为 UNCOMMITTED_LATEST时,启动Storm一直报错卡在这里,查看源码发现当调用 kafkaConsumer.poll(),如果没有获取到数据,会塞入treeMap一个null值,导致下一次 null.getLastOffset() 而报错。
目前我的解决办法是使用分支:1.x-branch,这个分支解决了上面的bug,但当前版本是 1.2.3-SNAPSHOT。地址:https://github.com/srdo/storm,在这个页面选择 1.x-branch,然后自己打包此分支的 storm-kafka-client.jar。
cd external\storm-kafka-client mvn clean package -DskipTests
注:Build此分支需要先安装 python、ruby、nodejs(文档上这么写的,下次试试不安装这几个打包下)。
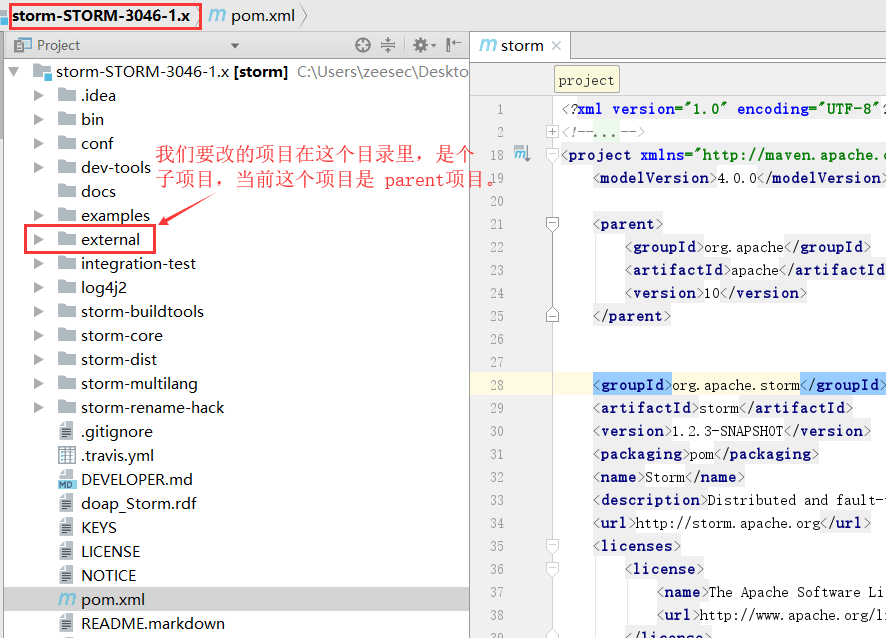
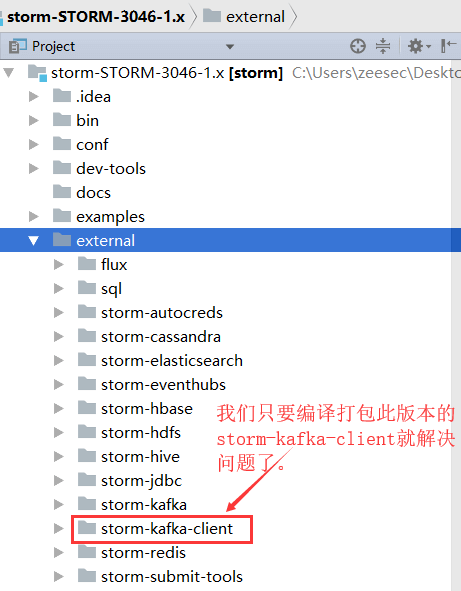
我们现在重新开个窗口,看下真正需要自己手动编译打包的项目 storm-kafka-client 吧:
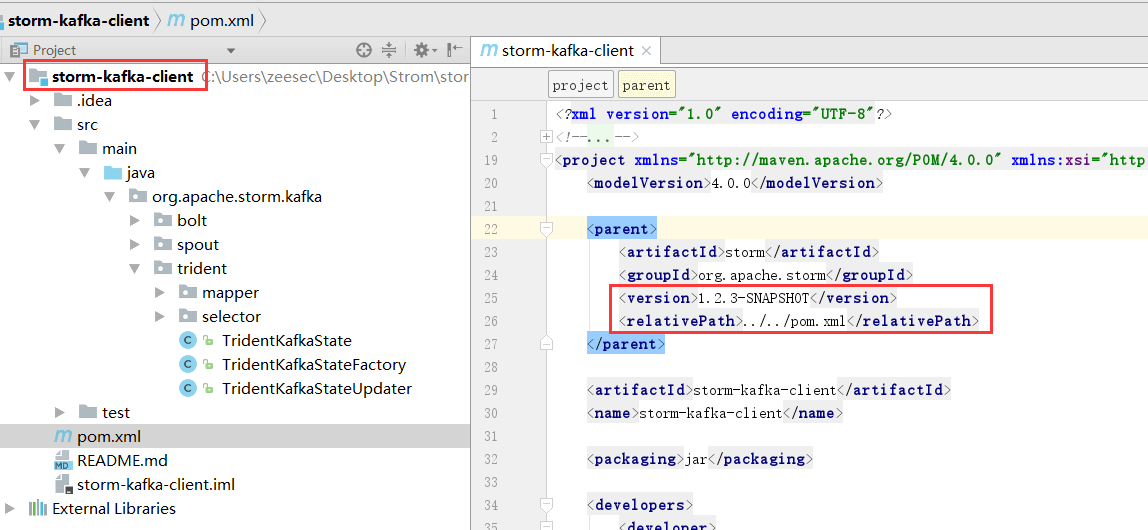
如果你有兴趣,可以下载下来慢慢研究storm源码,里面有各种examples,可以直接参考。多看看storm的源码,也是种享受,对你的写代码能力的提升是有很大帮助的哦!
8 storm -cp(classpath)
在实际工作中,当我想把下面 target下的 bundle、libs目录及目录里的依赖包提前放入storm集群时,出了点状况:
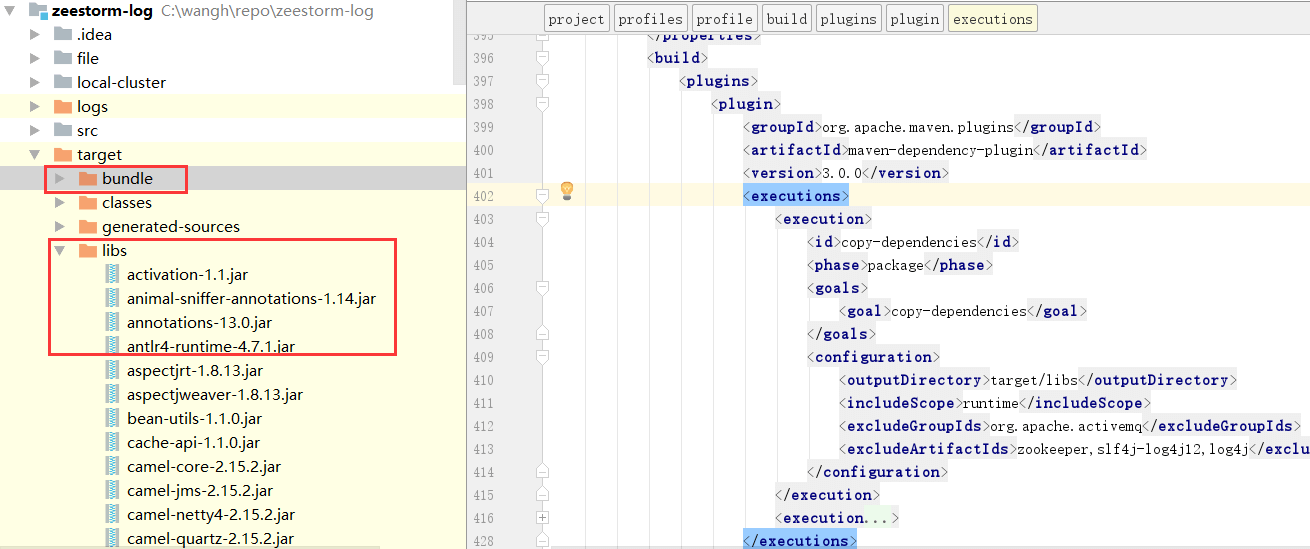
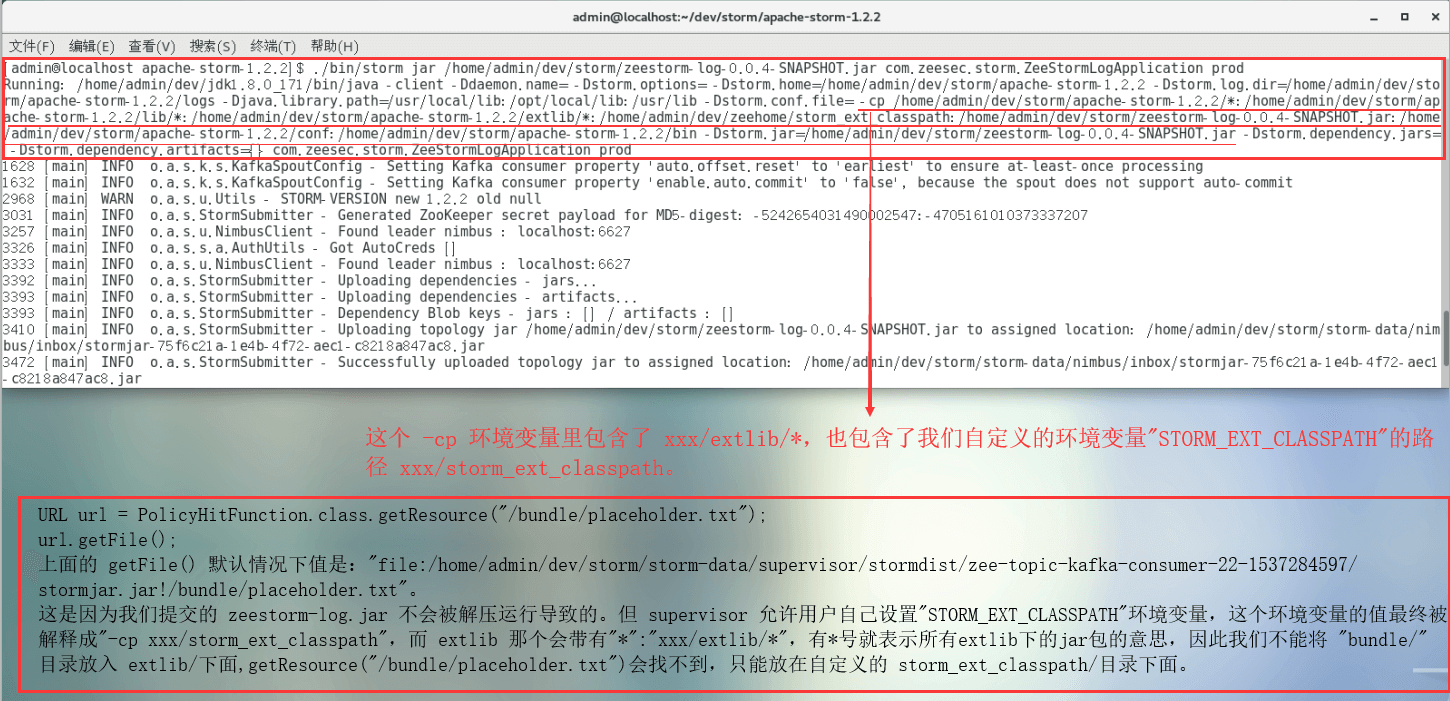
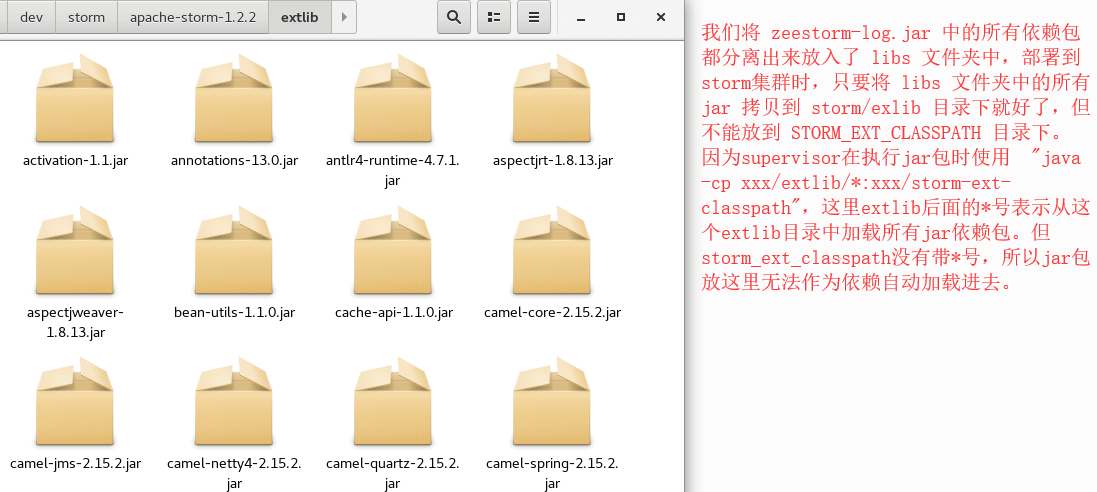
刚开始我是直接将 bundle文件夹直接放到集群的 extlib目录下的,但程序始终找不到bundle文件夹中的jar包,经过排查,这是由于 storm启动时使用了 storm -cp extlib/* ,就是这个“*”导致的:
9 Back Pressure(反压机制)
Storm和Spark Streaming都提供了反压机制。
- 对于开启了acker机制的storm程序,可以通过设置
conf.setMaxSpoutPending参数来实现反压效果,如果下游组件(bolt)处理速度跟不上导致spout发送的tuple没有及时确认的数超过了参数设定的值,spout会停止发送数据,这种方式的缺点是很难调优conf.setMaxSpoutPending参数的设置以达到最好的反压效果,设小了会导致吞吐上不去,设大了会导致worker OOM;有震荡,数据流会处于一个颠簸状态,效果不如逐级反压;另外对于关闭acker机制的程序无效; - 新的storm自动反压机制(Automatic Back Pressure)通过监控bolt中的接收队列的情况,当超过高水位值时专门的线程会将反压信息写到 Zookeeper ,Zookeeper上的watch会通知该拓扑的所有Worker都进入反压状态,最后Spout降低tuple发送的速度。
storm里面topology.max.spout.pending属性解释:
1.同时活跃的batch数量,你必须设置同时处理的batch数量。你可以通过”topology.max.spout.pending” 来指定, 如果你不指定,默认是1。
2.topology.max.spout.pending 的意义在于 ,缓存spout 发送出去的tuple,当下流的bolt还有topology.max.spout.pending 个 tuple 没有消费完时,spout会停下来,等待下游bolt去消费,当tuple 的个数少于topology.max.spout.pending个数时,spout 会继续从消息源读取消息。(这个属性只对可靠消息处理有用)
10 FAQ
10.1 contains a non-serializable field
提交到集群环境时,经常会遇到”contains a non-serializable field”这种错误。
这主要是对一个spout/bolt的生命周期不是很了解导致, 一般来说spout/bolt的生命周期如下:
- 在提交了一个topology之后(是在nimbus所在的机器么?), 创建spout/bolt实例(spout/bolt在storm中统称为component)并进行序列化.
- 将序列化的component发送给所有的任务所在的机器
- 在每一个任务上反序列化component.
- 在开始执行任务之前, 先执行component的初始化方法(bolt是
prepare, spout是open).
因此component的初始化操作应该在prepare/open方法中进行, 而不是在实例化component的时候进行。