1 解析原理
(1)假设待解析字符串为:ip route abc
(2)g4词法及语法规则文件如下:
ipRoute : 'ip' 'route' WORD
falWord
: ~( NEWLINE
| COMMENT_BOL
| ONE_WS_BOL
| TWO_WS_BOL
| THREE_WS_BOL
| FOUR_WS_BOL
| ANY_WS_BOL
| ILLEGAL )
;
WORD : ~[ \t\f\r\n]+ ;
WS : [ \t\f]+ -> skip ;
(3)解析原理
Antrl4 首先进行词法分析,语法分析是基于分析出来的词法的,即语法分析的时候是看不到Char的,只能看到第一个token。
这个例子解析 ipRoute 时,会由如“T__0、T__2、WORD”三个token来匹配。
这是因为语法规则上的字符串 ‘ip’ ‘route’,会被解析成token(如:T__0, T__2,具体在Lexer文件中),这是种默认行为。
这种默认行为可以理解成下面两个词法规则:
IP:’ip’
Route:’route’
并且这两个词法规则的位置在g4文件中任何词法规则的上面。
总结:因此我们可以将语法规则中的字符串认为是token,且定义在g4文件词法规则的最前面。
(4)扩展下例子
如果我们待解析的字符串改成:ip route route。此时,上面的 ipRoute 词法会匹配不了,这是因为这里的第二个 route 被优先匹配成了
T__1 这个token,而不是 WORD。可以修改下语法规则:
ipRoute : ‘ip’ ‘route’ falWord
此时就匹配上了,因为 falWord这个语法规则能匹配上 WORD、T__1,因为它用了 ~,即除了列出来的那些token,其他都去匹配。
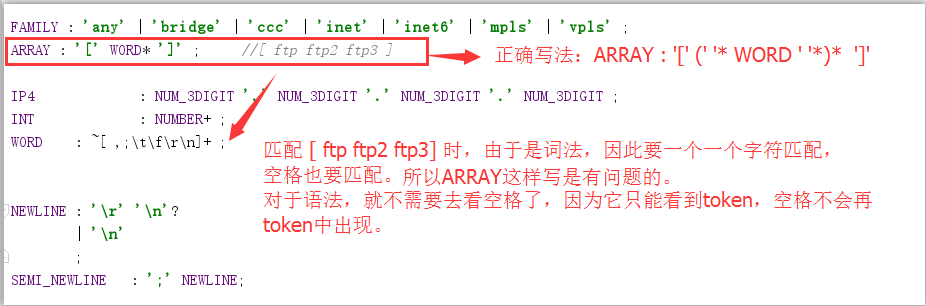
2 空格处理

3 词法和语法的匹配顺序规则
3.1 词法匹配时,优先按最长的匹配
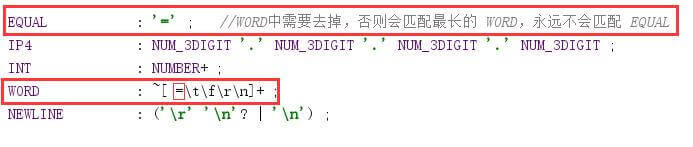
3.2 语法匹配时,按顺序匹配
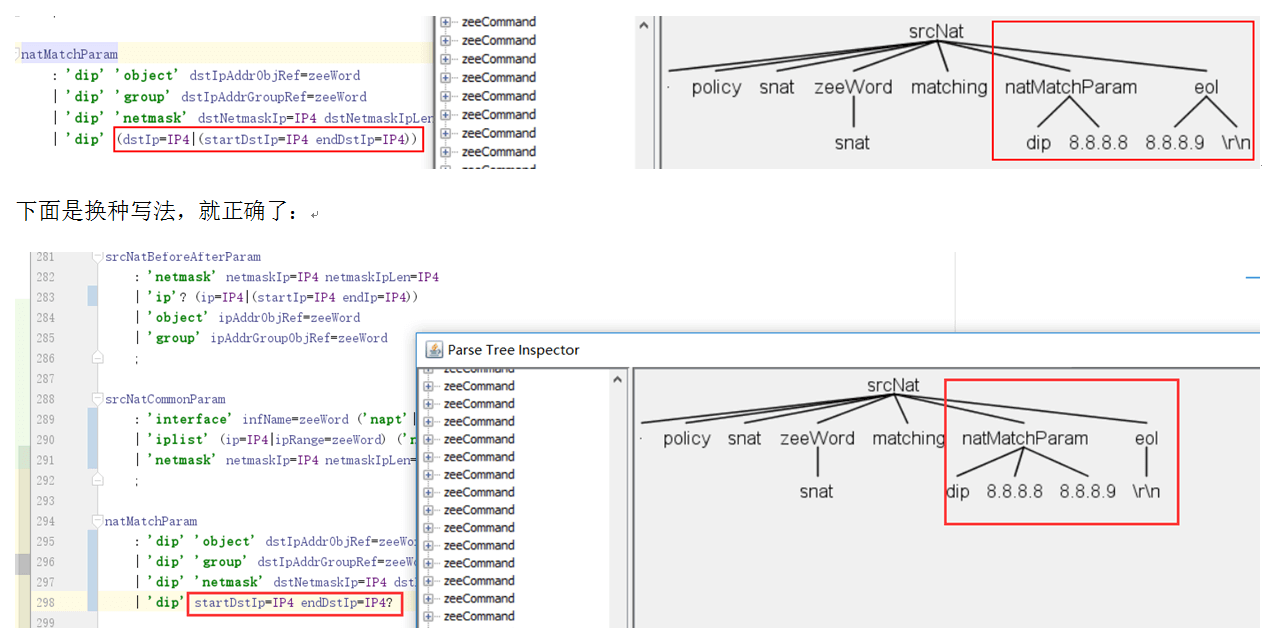
例如:”grammar1 | grammar2″,即使 grammar2 匹配的最长也没用,因为 grammar1 在前面。还有使用 +?时注意:

3.3 使用问号和竖杠的优先级问题
4 使用数组
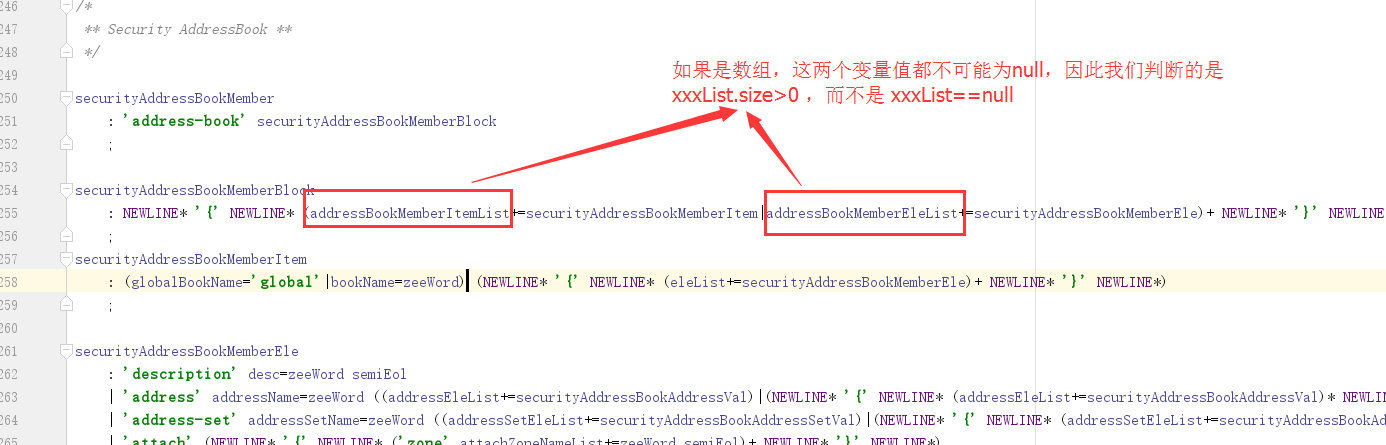
dstNatCmd : 'nat' 'destination-nat' name=falWord (eleList+=eleDstNat)* NEWLINE ;
使用+后,生成代码时,eleList 会生成一个数组对象,每个元素是token,如果等号右边是语法规则,那么对象元素是 context。
数组不可能为null值,如下图:
5 预测模式(PredictionMode.SLL 和 PredictionMode.LL)
有时候我在Antlrworks2里测试过的语法树,在代码里执行就报错,这是应为 Antlrworks2 可能使用了 PredictionMode.LL 模式解析的,但代码里我们必须要求设置 PredictionMode.SLL 以加快解析速度,遇到这种情况我们的做法是直接修改g4文件,而不是将 SLL 改为 LL。
5.1 SLL 模式
这种模式在预测时,会忽略当前解析上下文。这是解析速度最快的,而且对于大多数语法(grammars)都支持。但使用这种模式可能会带来grammar语法错误,就像上面说的。
当使用这种预测模式时,Antlr解析器可能正确返回一个解析树,也可能报告一个语法错误。
这种错误,可能是由于输入中的实际语法错误或语法和输入的特殊组合要求强大的LL预测能力来完成。
5.2 LL 模式
这种预测模式能够用于SSL预测解析失败的时候。这是最快的预测模式,可以保证语法和语法正确输入的所有组合的正确解析结果。
使用这种预测模式时,解析器将为所有语法正确的语法和输入组合做出正确的决策。但是,在语法确实不明确的情况下,此预测模式可能不会报告精确答案。
5.3 例子
routingEntry
: (stati='S>*' | connected='C>*' dest=IP4_W_LEN falText routingEntryClause
;
falText 是由多个 falWord 组成的。这里 falText 后面跟着 routingEntryClause 会出现语法不明确, falText 可以包含后面的 routingEntryClause 要匹配的内容,除非控制 falText 使用“饥渴”匹配。因此这里用SLL模式就会报语法错误。改用LL就没问题。
6 参数的使用
6.1 配置文件
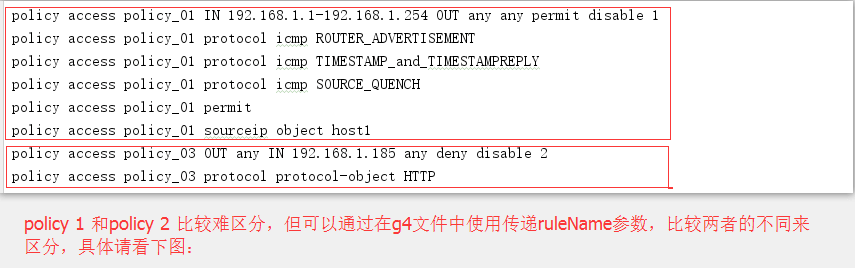
6.2 g4文件

7 注意点
7.1 Java关键字不能用于g4文件中
interface、static等java的关键字不能用于g4文件的变量中,如:

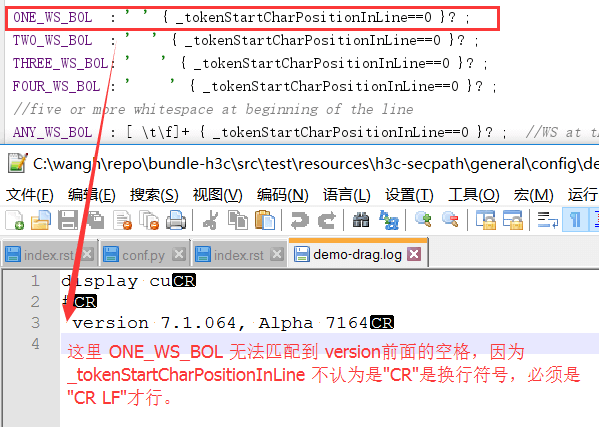
7.2 使用 _tokenStartCharPositionInLine 注意点
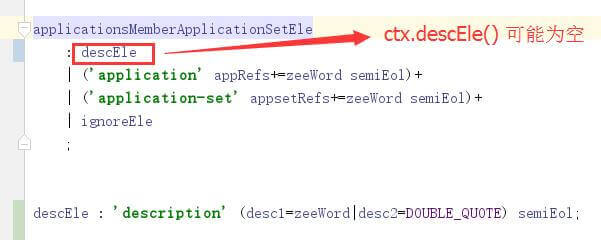
7.3 语法规则中子规则可能为空
7.4 双引号和单引号引起的问题

7.5 问号、星号使用需要特别注意

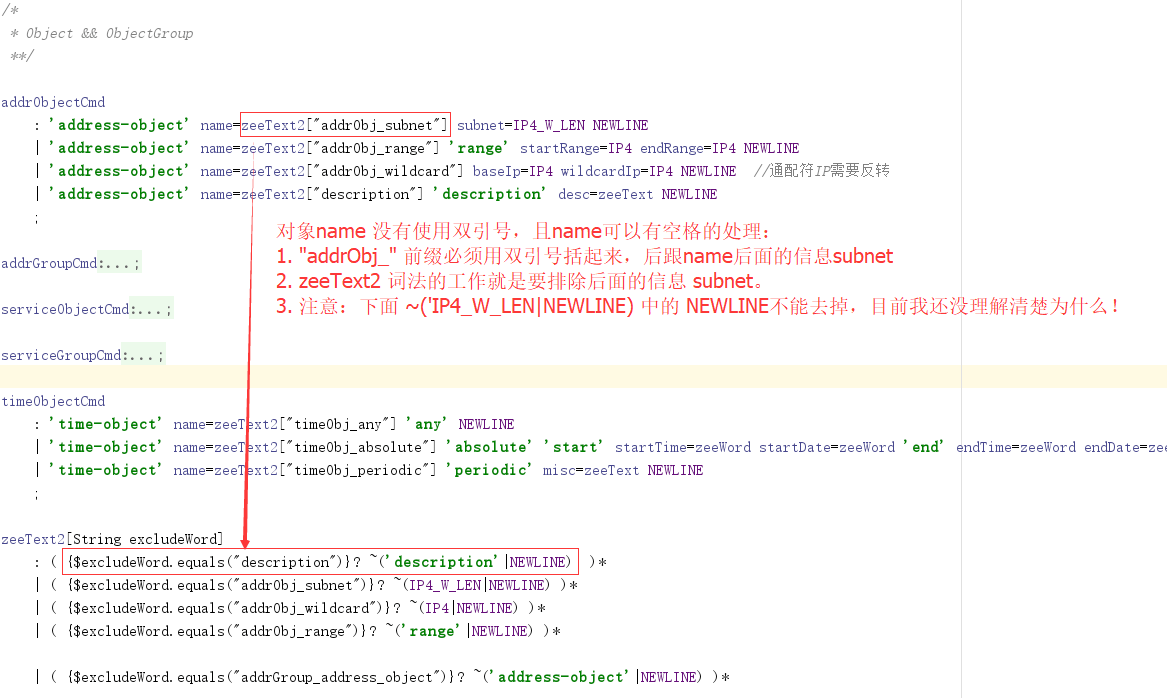
7.6 无双引号且要有空格的name的解析
7.7 语法、词法不要混了
7.8 左递归问题

7.9 赋值语法
// 正确写法 - 将每个token赋予 yamlText 变量。 START_TAG (mytext+=.)* END_TAG ; // 正确写法 - 上面的语法有点问题,最好写成这样。 START_TAG (mytext+=~END_TAG)* END_TAG ; // 错误写法 - block无法赋予 mytext。 START_TAG mytext=(.*) END_TAG ;
说明:
(a)”.”用在语法上时表示任意token。
(b)block无法赋值给变量,单个Token或者单个语法子规则都可以赋予变量。
7.10 嵌套循环问题

8 EOF 使用
在语法中,我们可以直接使用 EOF,例如:

9 分解词法规则与导入

10 Action
Actions 就是可以在语法rule(g4文件)里写的代码块,语法是 {…},在里面我们能访问 token 的 text。
stat: e NEWLINE {System.out.println($e.v);}
| ID'='e NEWLINE {memory.put($ID.text, $e.v);}
| NEWLINE
;
例如,$e.v 和 $ID.text。
$x.y 表示引用 x 元素 的 y 属性, x 可以是一个 token 也可以是一个 rule(这里指语法规则)。
$e.v refers to the return value from calling rule e.
If ANTLR doesn’t recognize the ycomponent, it doesn’t translate it. In this
case, textis a known attribute of a token, and ANTLR translates it to getText().
We could also use $ID.getText()to get the same thing.
e returns[int v]
: a=e op=('*'|'/') b=e {$v = eval($a.v, $op.type, $b.v);}
| a=e op=('+'|'-') b=e {$v = eval($a.v, $op.type, $b.v);}
| INT {$v = $INT.int;}
| ID
{
String id = $ID.text;
$v = memory.containsKey(id) ? memory.get(id) : 0;
}
|'('e')' {$v = $e.v;}
;
这个例子中,返回值指定了一个整数 v,使用使可以 {$e.v}。
【Token Attributes】
英文pdf 的 272 页提供了完整的 Token Attributes。
所有 token references 有一个预定义的、只读的属性集合。Action中可以访问这些属性通过 $label.attribute.
【所有Attributes】:text(String)、type(int)、line(int)、pos(int)、index(int)、channel(int)、int(int)。
【Parser Rule Attributes】
rule references(语法规则) 也预定义了一些只读属性。语法规则: $r.attr(r是语法规则引用)。
你也可以直接使用 $ 跟一个 attr 来访问当前语法规则下的属性,例如:
returnStat :’return’expr {System.out.println(“first token “+$start.getText());};
【所有Attributes】:text(String)、start(Token)、stop(Token)、ctx(ParserRuleContext)。
11 Demo
12 Antlr里涉及的一些专业词
- grammar 语法,一种形式化(formal)的语言描述。
- syntax 句法
- phrase 短语
- lexer 词法分析器
- parser 语法分析器
- parse tree 语法分析树,表示语法如何匹配输入的数据结构。
- tree walker 树遍历器
- top-down 自顶向下
- listener 监听器
- visitor 访问者
- backtracking 回溯
- semantic predicates 语义谓词
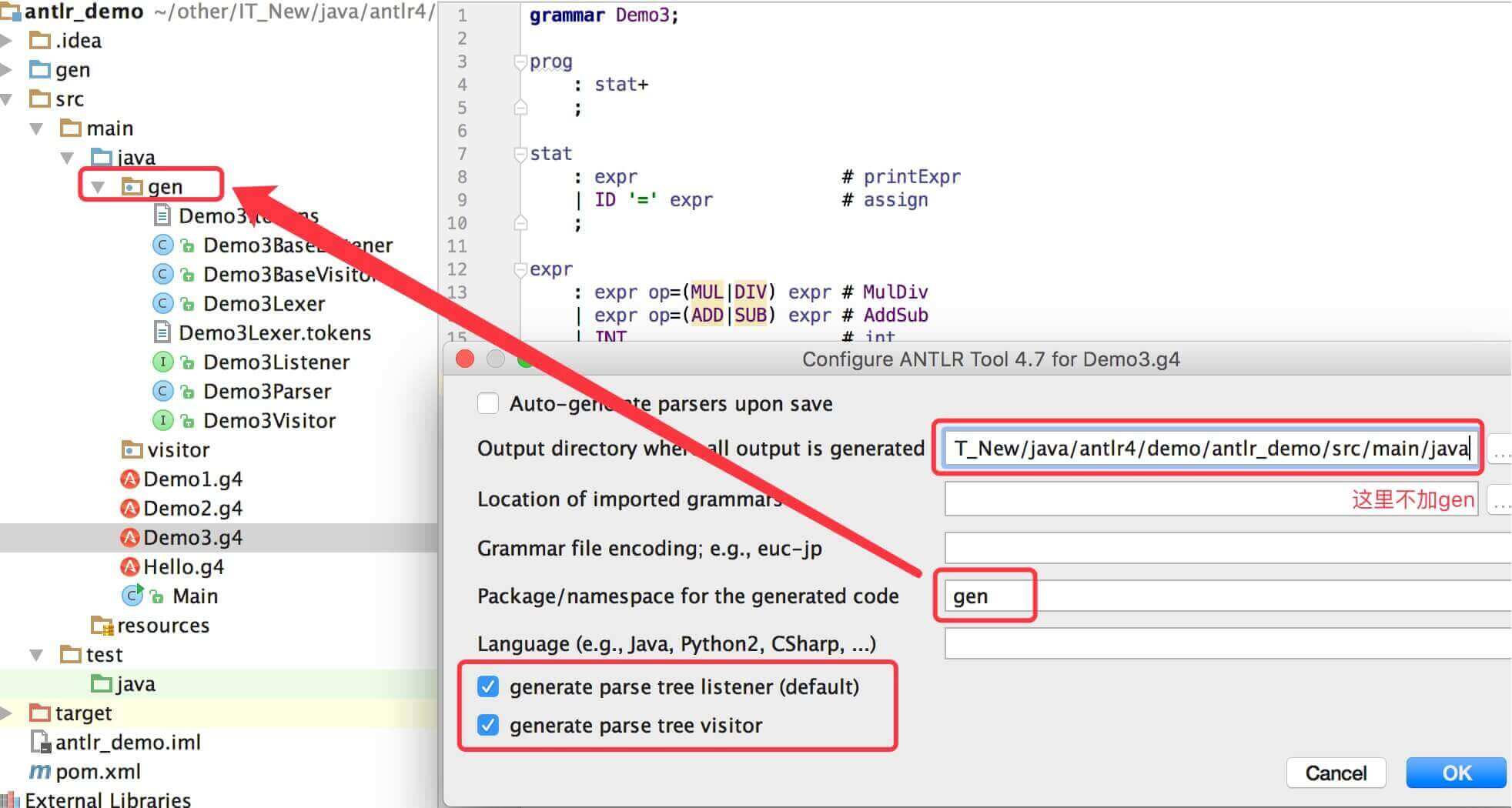
13 Idea 中配置 Antlr(工作中都用Antlrworks2了,不在Idea中分析处理了)